
小小的复习笔记
2018.11.04 初稿Instruction System Architecture和Cache部分
2018.12.24 增添Roaming in Computer System部分
Roaming in Computer System
Hardware Architecture
不同厂商出产的电脑的硬件组织各有不同,但是都保持着最基本的三个部分:中央处理单元(CPU)、输入输出系统(I/O System)和主存(Main Memory)。三个重要的部件由总线(Bus)连接,分享数据信息。
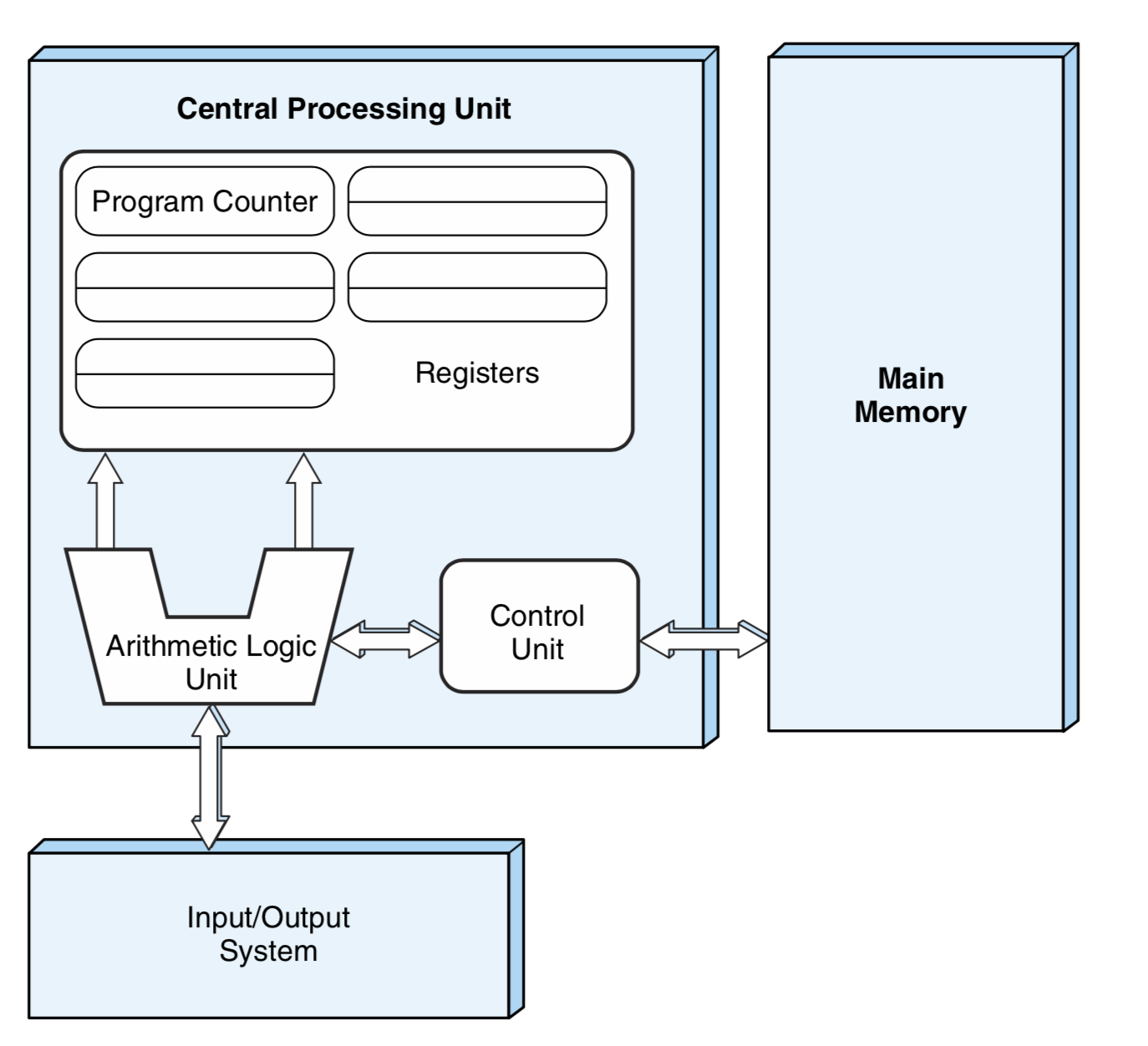
Central Processing Unit
CPU的任务是:提取指令、翻译指令、执行指令。其可分为两个部分:
- 数据通道
数据通道,顾名思义,是对数据的处理。计算机(Computer)之所以叫计算机,其本质就是Computing,数据通道由算数逻辑单元(Arithmatic Logic Unit)、若干寄存器(Register)组成。数据通道做的是执行指令。
- 控制单元
控制单元的作用就是做一名Dictator,去决定数据通道要做什么,从哪里取数据,把数据存去哪里,对这些数据究竟做什么操作。控制单元负责提取指令、翻译指令
Bus
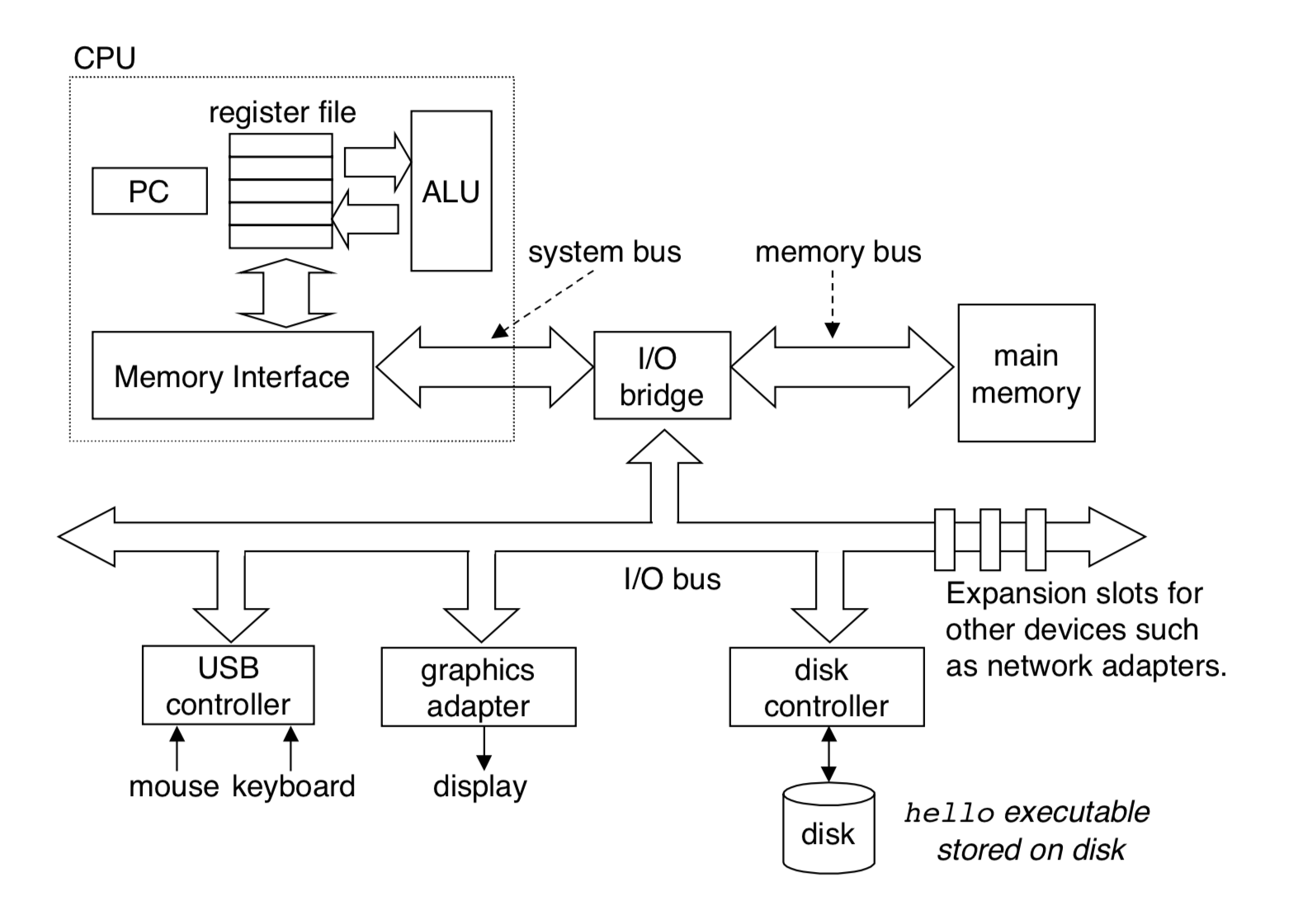
这张图将总线的重要性展示了出来。总线将CPU与其他部件连接起来,没有总线,不同部件之间就无法进行交流。总线可按功能、位置、是否由时钟控制分类。
- 典型的计算机总线按功能可分为四类:
- 数据总线
数据总线控制数据流动。
- 地址总线
地址总线指出数据的位置。
- 控制总线
因为在冯诺依曼体系结构中,只有一根总线连接各个部分,所以每次只有一个部件能占用总线,为了能够统一协调,因此设计控制总线,来控制每个部件使用其他总线。
- 电源线
- 按总线位置可分为三类:
- 内总线(系统总线)
- 外总线(扩展总线)
- 局部总线
- 按是否有时钟控制,可分为两类:
- 同步总线(Synchronous)
- 异步总线(Asynchronous)
因为只有一个设备能够占用总线,所以如何选择占用设备,就需要一个机制。我们将这个机制成为总线仲裁机制(Bus Arbitration)。一般分为四种:
- 菊花链仲裁方式
- 集中式平行仲裁方式
- 采用自选择的分配式仲裁方式
- 采用冲突检测的分配式仲裁方式
Main Memory
内存需要注意两点:
- 编址方式
- 寻址方式
I/O System
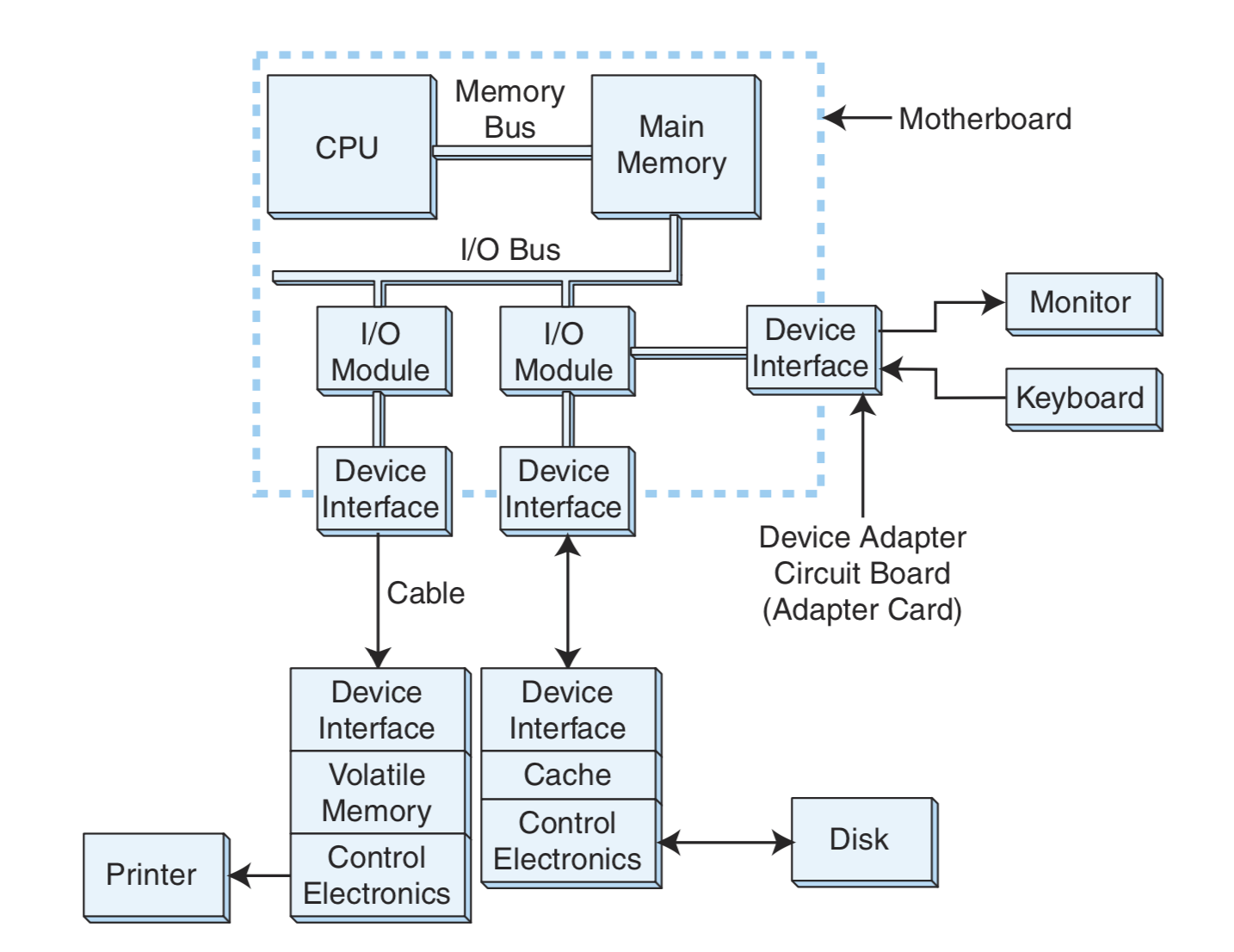
I/O设备是连接任何计算机的桥梁。
I/O设备不直接与CPU接触,而是通过设备接口(Interface),将I/O设备的信号和计算机内部的信号转换成两者看得懂的信号。
整个过程可以简单地看作:
CPU——>Interface——>I/O Device
CPU通过输入输出寄存器来和I/O设备交流,而一提到数据,就不得不解决数据的存储问题,而存储问题就得牵扯到数据编址。一般的输入输出编址有两种方式:
- 内存交换映射(Memory-mapped I/O)
就是把I/O数据放在内存映射表里,处理I/O数据和处理内存数据是一样的。
- 指令实现的输入输出(Instruction-based I/O)
用特殊的输入输出指令来控制数据传输。
Function
Instruction System Architecture
指令系统体系结构详细规定了计算机可以执行的每条指令及其格式,相当于是为软件和硬件提供了接口。
更详细的内容在文后。
Interrupt
中断机制是非常有必要的,为什么有必要呢?假设一个人在打字,每一个字符会被CPU读取然后在屏幕上显示,如果这个人打得非常快,那么CPU可能处理不过来。如果CPU还在处理一个字符的时候另一个字符已经敲进来了,那么CPU就不会处理这个字符;反之,如果打字非常慢,那么CPU就会不停地读取同一个字符显示在屏幕上。
所以我们需要一种机制来告诉CPU,“我准备好了!”(脑补海绵宝宝)、“我结束了!”。这就是中断机制的初衷。
计算机中有三种类型的中断:
- 内部中断
- 外部中断
- 软件中断
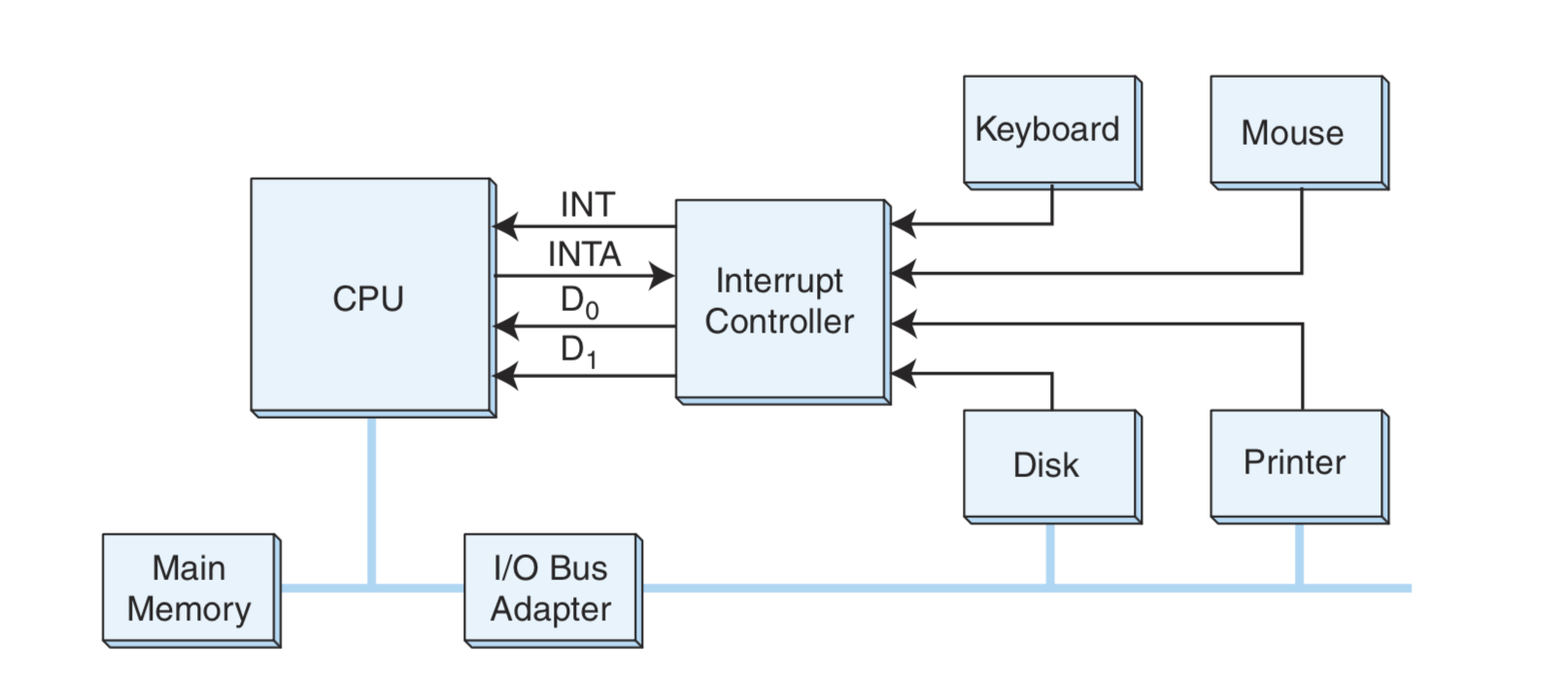
如图,众多的I/O设备由终端控制器控制着,设备比如说键盘向中断控制器说“我准备好了!”,然后中断控制器向CPU传达键盘的愿望:“他准备好了!”,CPU如果准备好接收信息,就会发送一个INTA信号,回复中断控制器:“我知道他准备好了!告诉他我也准备好了!让他把数据传过来!”,然后中断控制器就会告诉键盘,键盘就会把数据$D_0$传给CPU处理。
Fetch-Decode-Execute
在MARIE模型机中,程序的取指-译指-执行如下图
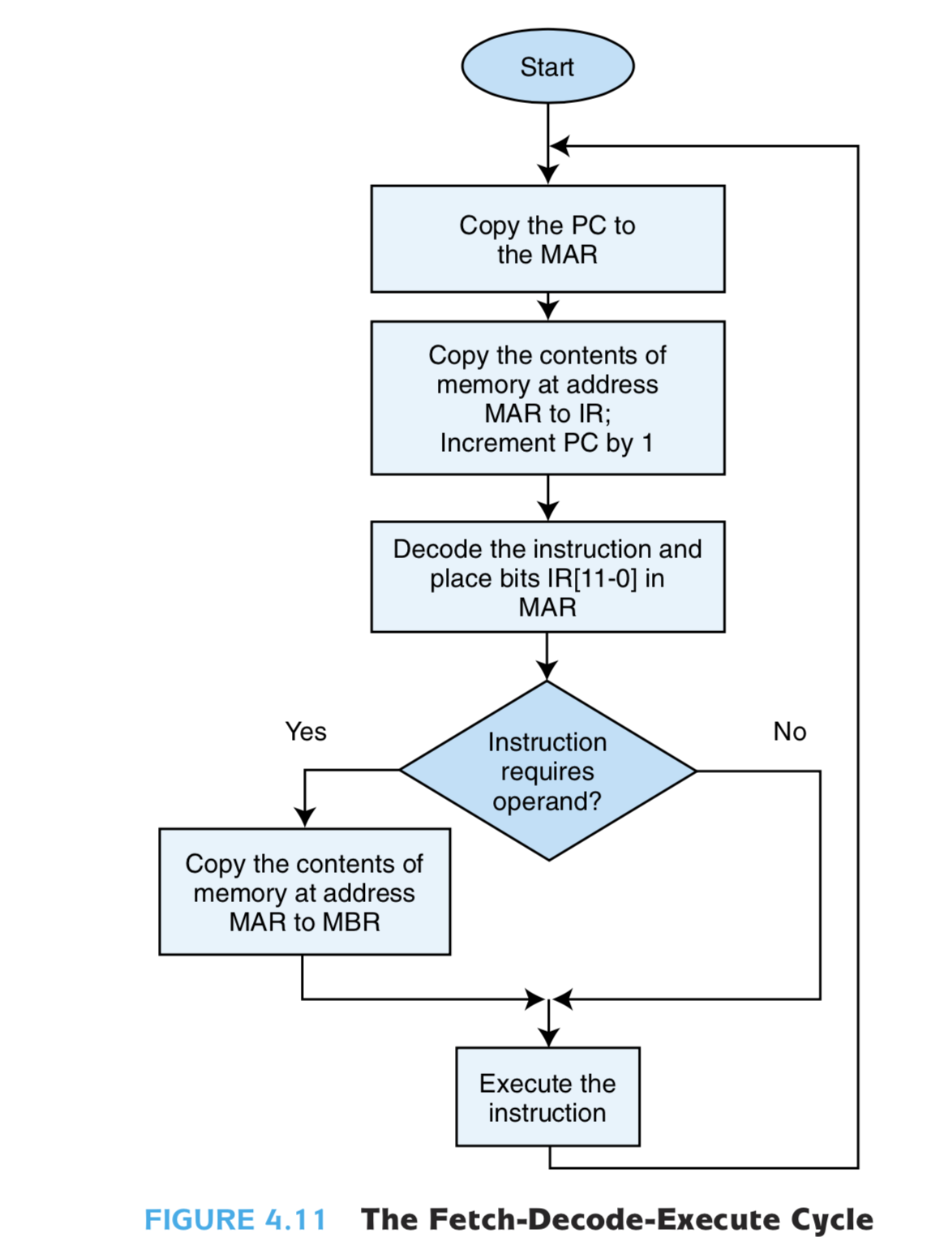
译码的方法有两种:
- 硬连线控制(Hardwire control)
- 微程序控制(Microprogramming)
Assembler
我们知道,实际上在取址的时候,程序就已经是机器码了,所以在Fetch-Decode-Execute之前,还有一段将高级语言翻译成机器码的操作,对于汇编语言来说,需要经过编译器(Assembler)的处理。
在使用汇编语言时,我们往往会对某个变量取名为A、B、C(Whatever……),这就意味着编译器需要通读两遍源代码,才能生成二进制文件。
第一次会建立一个符号表,将变量符号(A、B、C)与其对应的地址记在表上,同时将能编译的都编译成二进制码,这时的二进制码文件,关于变量的数据地址是不知道的,所以空着。
第二次通读,再把空着的变量地址根据符号表填进去。举一个例子:
我有如下程序

在第一次通读后,会生成关于X、Y、Z的符号表:
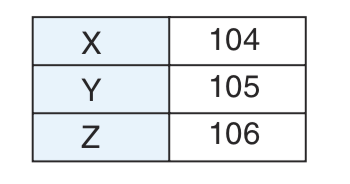
这时关于X、Y、Z的地址我们是不知道的,所以第一次通读后形成的二进制码是这样的:
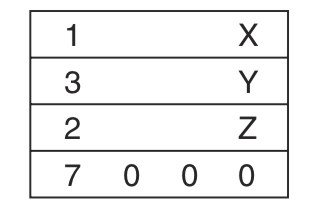
第二次同读后,将符号表中的地址一一填入空白处:
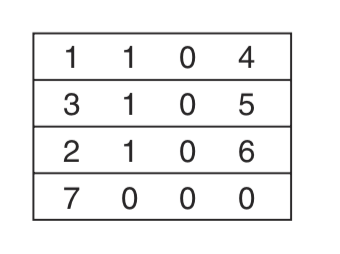
至此,编译结束。
Instruction System Architecture
本章讨论指令系统体系结构。
最开始的一件事,在创造指令前,我们需要给他安个家:指令要存在哪儿?要怎么存?这就涉及到CPU的数据存储的体系结构。
其次,家找好了,一心一意给造指令吧。我们必须要规定指令的格式,包括指令类型、指令长度、指令顺序。
指令自己的格式指定好了,接下来就要明确指令如何在数据上发生作用,而要发生作用,首先得取得数据,而取得数据,不能单纯在指令地址域指定数值大小,你总得找一个地方把过程数据、结果数据储存起来,这就涉及到寻找数据的存储器地址。寻址方式,我们就可以想到:1.直接寻址;2.立刻寻址;3.间接寻址;4.变址寻址和基址寻址。
所有事情都做好了,我们会开始思考,能不能让指令执行起来更有效率?这就引出了流水线的概念。
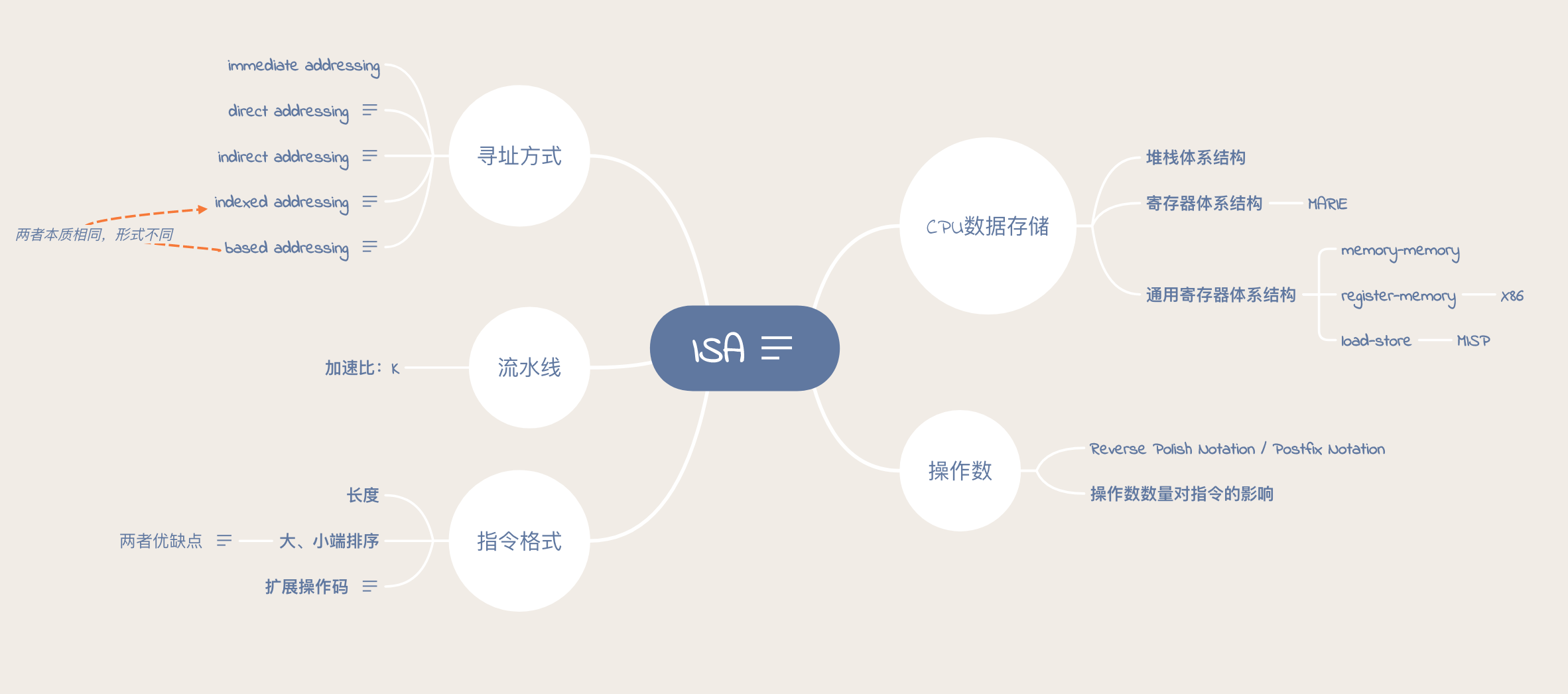
寻址方式
- immediate addressing
- direct addressing
在指令中直接指定所需要的数据在存储器中的地址。
- indirect addressing
地址的地址:指令地址域中所指的是一个存储器地址,这个存储器地址指向的数据是存储着所需数据的存储器地址。
- indexed addressing
变址寻址需要额外一个变址寄存器,其中存有偏移量(Displacement),而指令地址域是基地址,数据的地址是两者相加。
- based addressing
基址寻址,首先需要一个基址寄存器,存储基址,而指令地址域则是一个偏移量。
其中,最后两种本质上是相同的,形式上不同而已。
流水线
加速比:K
指令格式
大、小端
大端:符号位在放在首位,很容易判断正负;
小端:强制转换数据不需要调整字节内容。
扩展操作码
我们想,应该给操作码opcode多少空间?给得太长,操作码数量会变得丰富,但空间利用率不高;给得太小,效率挺高,但指令数量就变少了;我们给一个灵活的可变大变小的空间吧,译码又会很麻烦。我们想到Expanding Opcode,相当于可变长的操作码,思想一般是:给指令一个固定的空间,首先最好取短操作码,这时候操作数的空间就变多了,我们可以用多个操作数,来简化操作码的数量,如果需要更多的操作码,我们就expand opcode,压缩操作数。
操作数
Reverse Polish Notation / Postfix Notation
操作数数量对指令的影响
CPU数据存储
- 堆栈体系结构
寄存器体系结构
- MARIE
通用寄存器体系结构
- memory-memory
- register-memory
- X86
- load-store
- MISP
Cache
Memory Hierarchy
首先我们看到存储器的层次结构,可以发现是呈现金字塔状的,为什么呢?因为一种介质的速度越快,就会越贵,同时也消耗更多的电量,所以一般容量比较小。而 CPU 和内存之间的速度差距越来越大,所以好的程序都会尽可能利用局部性。而根据这些特性,引申出了安排存储的方式,称为金字塔式存储体系(Memory Hierarch)。
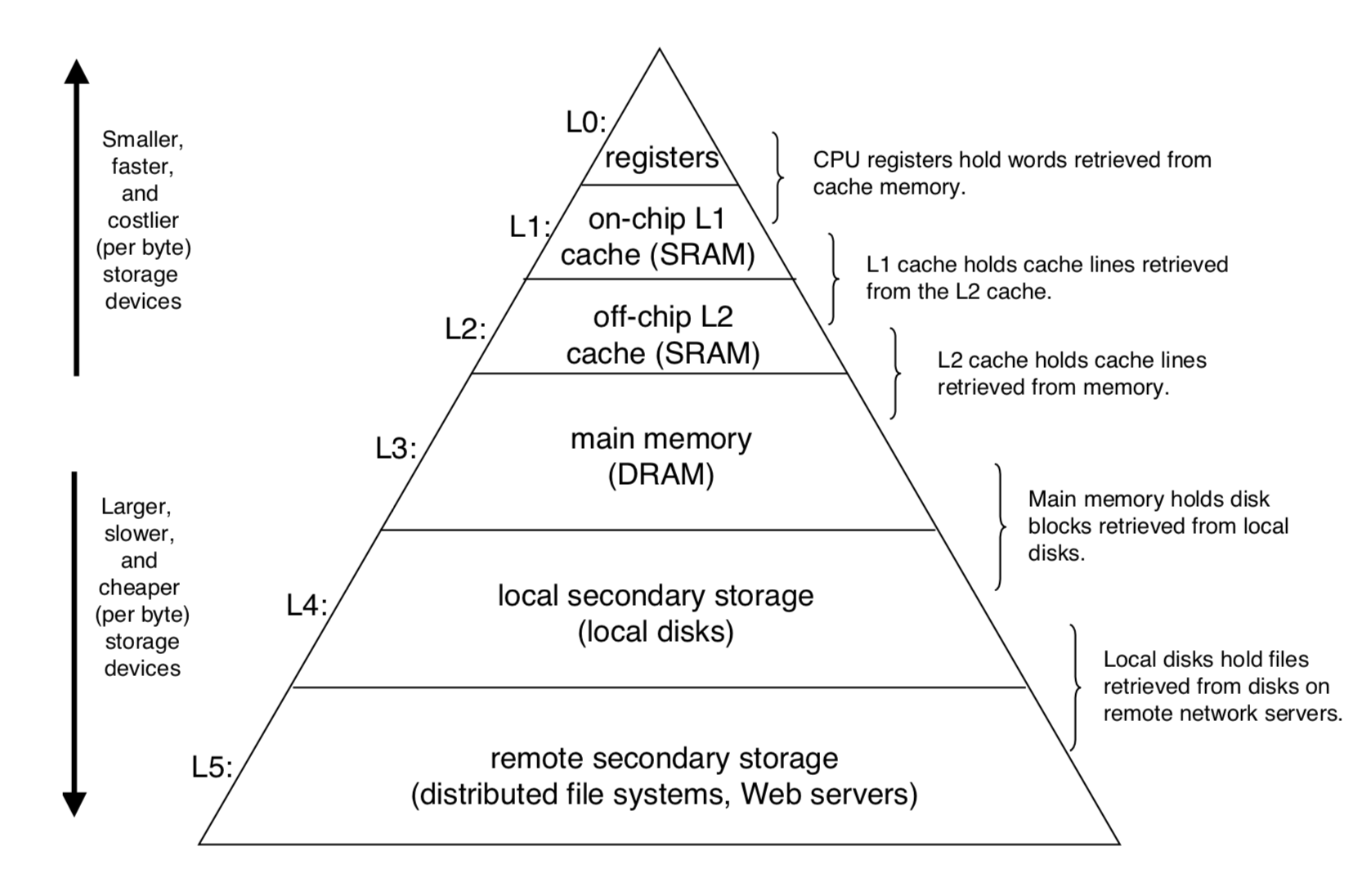
这里就涉及到一个技术:缓存。缓存可以看作是把大且缓慢的设备中的数据的一部分拿出来存储到其中的更快的存储设备。由局部性原理,CPU会更倾向于访问第 k 层的数据,而非第 k+1 层,这样就减少了访问时间。
举个例子,CPU取值的时候,会首先到L1Cache中找,找不到的话,就到L2Cahche中找,如果找到了,就取那一大块的数据放到L1Cache中去,然后再从L1Cache取想要的数据。为什么要取一大块放进L1Cache里而不是直接取需要的数据到CPU呢?这是因为程序往往会使用相同区域内的数据,而且程序往往会重复使用某些数据,所以直接取一大块,这一大块数据有很大可能是程序需要的大部分数据,所以CPU就不需要每次都去L2Cache找数据了。
注意,缓存是一个相对概念,在金字塔式存储体系中,每一层都可以看作是下一层的缓存。而高速缓存一般指的是L1Cache,L1集成在CPU中。
地址
CPU对数据的操作首先是要得到这个数据,而得到这个数据就得知道这个数据在哪儿,要知道这个数据在哪儿,就得知道这个数据的地址。所以接下来我们说说数据地址。
我们由前面可知,CPU取指–译指—执行,在译址过程中,会生成一个主存储器地址,但是我们知道,CPU是去Cache中取数据的,所以怎么用主存地址去Cache中找数据呢?而且,Cache的空间肯定比主存空间小,怎么把主存的每一个地址表示在Cache中呢?
Cache的内部设计
我们先来看看Cache的内部结构是怎么样的:

我们可以看到,缓存的空间被分成了S个集合,每一个集合中有E行,每一个行被分为三部分:V、tag、数据(data)。
Q:为什么要分成包含很多行的集合?
A:因为局部性。我们要把需要数据周围的一大块数据拿过来,每一个集合存放一大块数据,符合局部性原理。
Q:为什么行要分成三部分?
A:V表示合法性(Valid),当合法性为1时,数据可以取,合法性为0时,数据不能取。而tag确定的是集合,比如Cache有4个集合,那么tag就有2位,00表示第0个集合,01表示第一个集合……。
主存的地址设计
当CPU要一个数据时,它会生成一个主存的地址,而这个主存的地址就可以根据上面进行的架构来设计。

这是主存的地址分布,注意不要和缓存的内容分布搞混。
知道了Cache内容的设计,主存地址的设计意图就很明显了,t用来匹配相应的行,s用来匹配相应的集合,b表示在某集合某行中第几个数据才是我们要的数据。
直接映射高速缓存
当E=1时,即每个集合只有一行时,主存的每一块也就直接对应到Cache的一块,这就叫直接映射高速缓存(Direct Mapped Cache)。
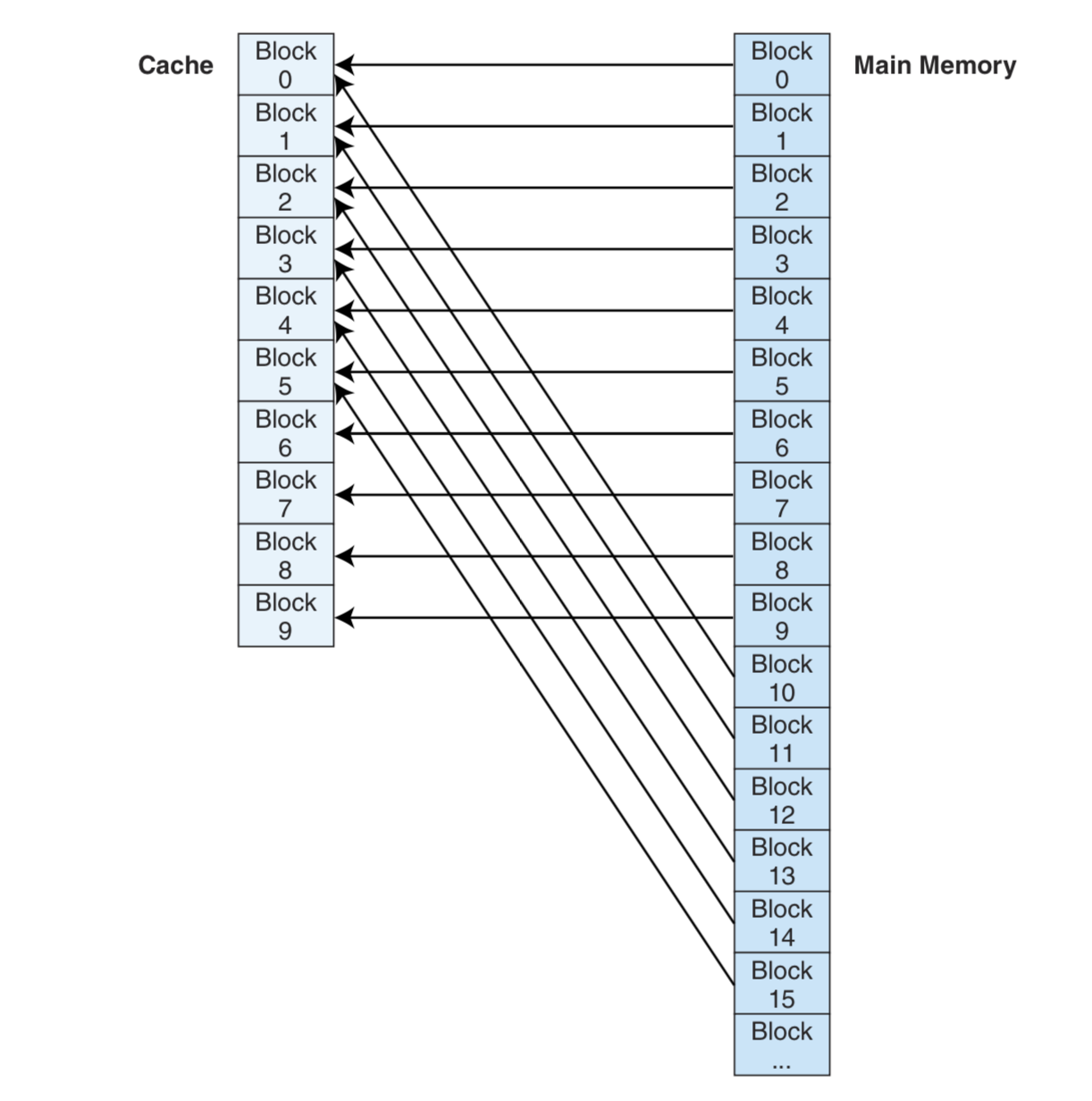
要寻找数据,则是如下图所示:

全关联高速缓存
全关联高速缓存非常极端,他干脆不分在Cache中的集合,随便存在哪儿都行,所以主存的地址就变成了两部分:tag和block,没有了set。
组关联高速缓存
当 E 大于 1 时,也就是每个 set 有 E 个 line 的时候,称之为 E 路联结缓存,也叫E路组关联高速缓存(E-way set associative Cache mapping)。
写入
在整个存储层级中,不同的层级可能会存放同一个数据的不同拷贝(如 L1, L2, L3, 主内存, 硬盘)。如果发生写入命中的时候(也就是要写入的地址在缓存中有),有两种策略:
- Write-through: 命中后更新缓存,同时写入到内存中
- Write-back: 直到这个缓存需要被置换出去,才写入到内存中(需要额外的 dirty bit 来表示缓存中的数据是否和内存中相同,因为可能在其他的时候内存中对应地址的数据已经更新,那么重复写入就会导致原有数据丢失)
在写入 miss 的时候,同样有两种方式:
- Write-allocate: 载入到缓存中,并更新缓存(如果之后还需要对其操作,这个方式就比较好)
- No-write-allocate: 直接写入到内存中,不载入到缓存
这四种策略通常的搭配是:
- Write-through + No-write-allocate
- Write-back + Write-allocate
其中第一种可以保证绝对的数据一致性,第二种效率会比较高(通常情况下)。
虚拟存储器
Reference:
Computer System A Programer Perspective
Essentials Of Computer Organization And Architecture


- 本文作者: YA
- 本文链接: https://shiyuang-scu.github.io/2018/11/04/计算机组成与体系结构/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!