
本文介绍了一种文本生成的方法,关键技术为生成对抗网络(GAN)和强化学习(RL)。
内容主要包括方法的数学原理、实现思路和具体实现细节。
2019.3.3 初稿 初定内容大纲
2019.3.11 增加 循环神经网络(Recurrent Neural Network RNN) 内容
2019.3.17 增加 长短时记忆模型(Long Short-Term Memory LSTM) 内容
关键技术
我们要使用的是LSTM,但是LSTM是一个RNN模型的改进,其目的是为了适应原始RNN梯度消失、文本相关性等缺点,所以首先我们要知道什么是RNN。
循环神经网络(Recurrent Neural Network RNN)
【Karpathy】The Unreasonable Effectiveness of Recurrent Neural Networks
概述
- 序列模型
- 能够体现序列元素之间的相关性
- 相关性的体现,使其被运用于文本生成、机器翻译、语音识别等
RNN与普通神经网络(Vanilla Neural Networks)不同的是,它不是单一的input-hidden layer-output的形式,而是输出、隐层、输出都可实现序列化,如下图
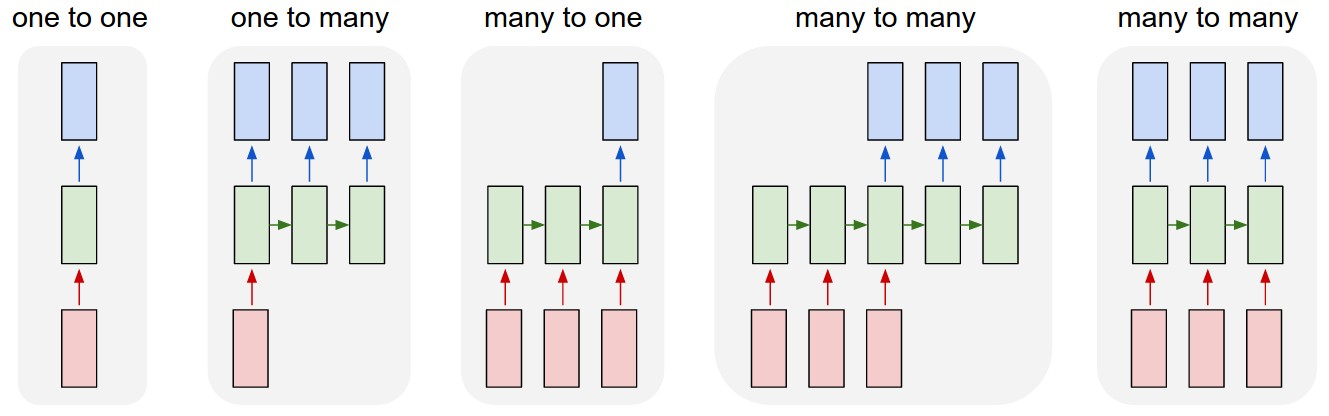
蓝色方框是output,红色为input,绿色则是中间层,我们可以把绿色中间层理解成input的中间状态(state)。
(1)普通神经网络只是one-to-one的关系,而RNN则有其他四种形式:(2)one-to-many可以理解成由图片作为输入,输出对图片的文字说明(e.g. 图片描述、诗歌),其中每一个蓝色方框都是一个词;(3)many-to-one可以理解为对一句话做情感分析;(4)many-to-many的第一种形式则可以理解为机器翻译;(5)many-to-many的第二种形式则可以理解为视频分类(对视频的每一帧进行分类或者预测)。
我们通过上图,可以看到RNN的另一个特点:每一个中间层,或者说每一个 $input$ 状态都与前一个 $input$ 状态相关,这就体现了相邻 $input$ 之间的相关性。
比如说我输入一句话作为我的 $input$ ,”猫吃鱼“,其中 $input_1$ ”猫“, $input_2$ ”吃“, $input_3$ ”鱼“,”猫“的中间状态由前两个 $input$ 的中间状态决定,即,”吃“”鱼“这两个 $input$ 和”猫“有关,这符合我们的逻辑,猫不就是吃鱼的么。
上下文构成了联系,而不是被单一孤立开来,RNN实际上实现了部分我们对智能体的期待,所以Karpathy也说,RNN是最令他激动的模型。
模型
我们用$x^{< i >}$来表示第 $i$ 个输入值,$y^{< i >}$来表示第 $i$ 个输出值,举个例子,我有一句话:
$$My\ name \ is\ ClowNaxcvd\ Shi$$
那么每一个单词分别对应一个输入值,即,$My$ 对应 $x^ {< 1 >} $,$name$ 对应 $x^{< 2 >}$……
我想要判断这句话中有哪些单词表示名字,那么$x^ { < t > }$对应的输出值就为 $y^ { < t > }$ 。如果是名字,$y^ { < t > } $就等于1,否则就等于0。
因为计算机只认数字,其他的东西一律看不懂,所以还涉及到将单词向量化的问题。简单来说,就是将文字数字化,所以我们输入的$x^ { < t > }$实际上应该是一组数字,不是单词。
我们首先要将单词变成数字,这一点知道就好,为了方便理解,我们就当计算机识字好了。
对于一般神经网络来说,如果我们要做名字的识别,我们一般会这样做:
将 $x^{< 1 >}$ 传入神经网络,输出 $y^{< 1 >}$,
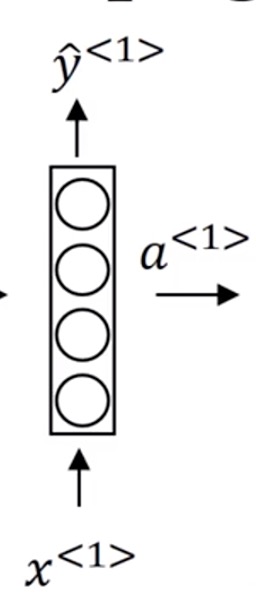
图中 $a^{< 1 >}$ 表示中间状态,一般会用激活函数,将其变成$y^{< 1 >}$。
同理,将 $x^{< 2 >}$ 传入神经网络,输出 $y^{< 2 >}$,
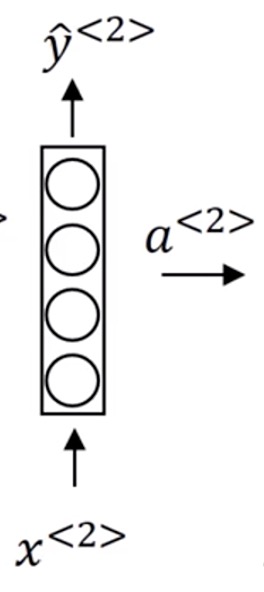
这样做的问题很明显,我们不能将前一个输入和后一个输入联系起来,每一个单词都是孤立的。但是我们可以看到,$ClowNaxcvd$ 和 $Shi$ ,我们不会将 $Shi$ 理解成一个东西,因为它跟在 $ClowNaxcvd$ 后面,符合姓名的逻辑。
于是我们将这两者结合:
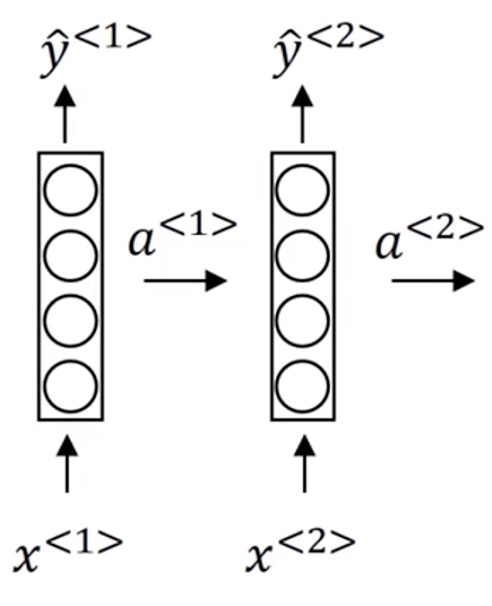
$x^{< 1 >}$ 的中间状态 $a^{< 1 >}$ 传给 $x^{< 2 >}$,共同计算出它的中间状态 $a^{< 2 >}$,然后再通过$a^{< 2 >}$计算出 $y^{< 2 >}$。
我们将其推广到一般情况,如下图。其中我们看到一开始有一个 $a^{< 0 >}$,是因为$a^{< t >}$ 是由$a^{< t-1 >}、x^{< t >}$决定的,而 $a^{< 1 >}$之前已经没有输入值和中间值了,所以我们额外加一个 $a^{< 0 >}$ ,这样 $a^{< 1 >}$ 就合乎逻辑了。
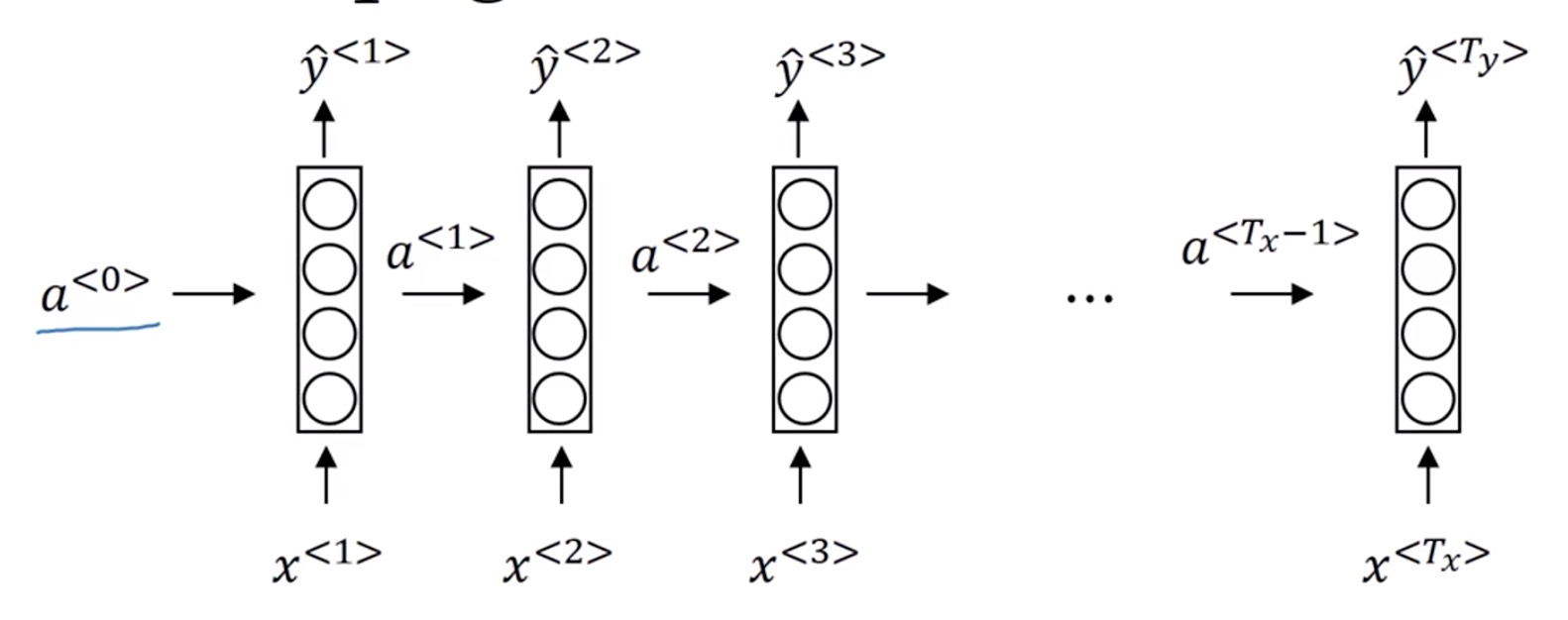
逻辑讲清楚了,接下来我们看该怎么计算出 $a^{< t >}$ $y^{< t >}$。
前向传播
我们从左向右看,一般开始先输入 $𝑎^{<0>}$,它是一个零向量。接着就是前向传播过程,先计算激活值 $𝑎^{<1>}$,然后再计算 $y^{<1>}$。
$$𝑎^{< 1 >}=g_1(𝑊 _ {𝑎a}a^{< 0 >}+𝑊 _ {a𝑥}x^{< 1 >}+𝑏 _ a)$$
$$\hat{𝑦}^{< 1 >} =g_2(𝑊_{ya}a^{< 1 >} +𝑏_y) $$
我将用这样的符号约定来表示这些矩阵下标,举个例子, $W_{ax}$第二个下标$x$意味着 $W_{ax}$要乘以某个$x$类型的量,然后第一个下标$a$表示它是用来计算某个$a$类型的变量。同样的,可以看出这里的 $W_{ya}$乘上了某个$a$类型的量,用来计算出某个$y$类型的量。
循环神经网络用的激活函数经常是 tanh,不过有时候也会用 ReLU,但是 tanh 是更通常的选择,我们有其他方法来避免梯度消失问题,我们将在之后进行讲述。选用哪个激活函数是取决于你的输出𝑦,如果它是一个二分问题,那么我猜你会用 sigmoid 函数作为激活函数, 如果是𝑘类别分类问题的话,那么可以选用 softmax 作为激活函数。不过这里激活函数的类型取决于你有什么样类型的输出$y$,对于命名实体识别来说𝑦只可能是 0 或者 1,那我猜这里第二个激活函数 $g$ 可以是 sigmoid 激活函数。
更一般的情况下,在 $t$ 时刻,
$$a^{< t >}=g_1(𝑊 _ {aa}a^{< t-1 >}+𝑊 _ {ax}x^{< t >}+b _ a)$$
$$\hat{y}^{< t >} =g_2(𝑊_{ya}a^{< t >} +b_y) $$
下图提供了更直观的过程。其中 $h$ 就是 $y$ ,只是不同人的表示方法有所差异而已,这点不用细究了。
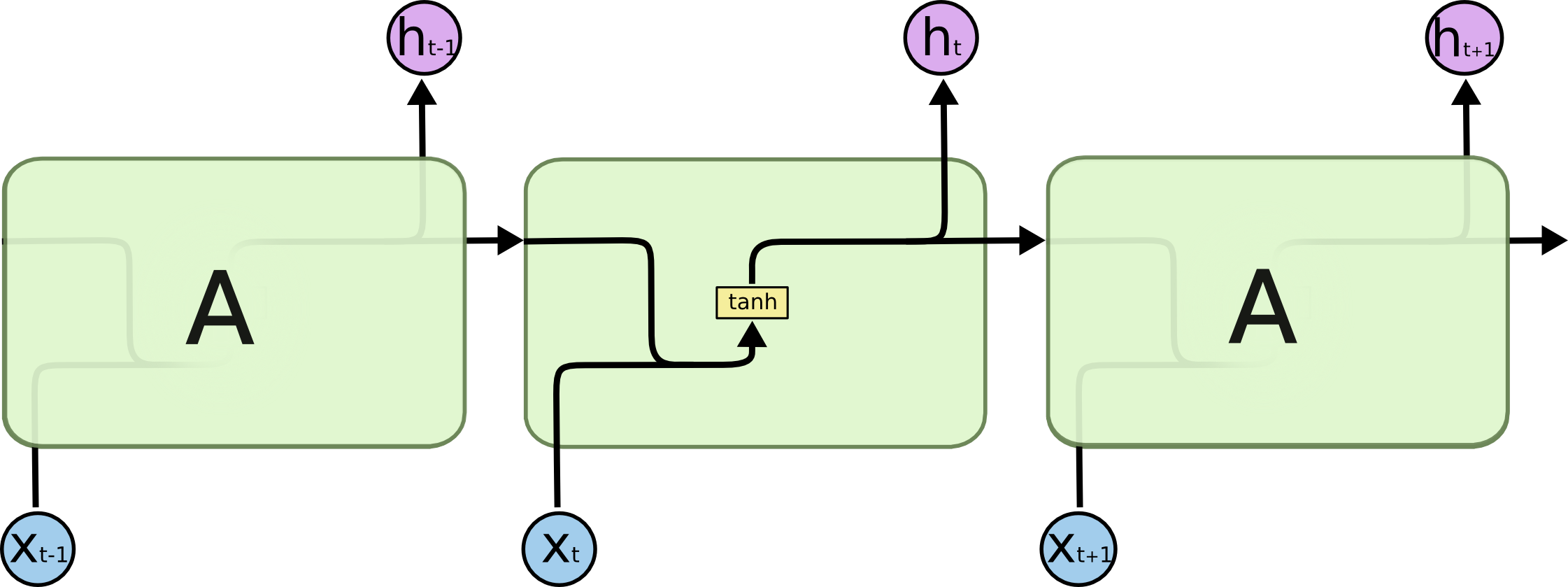
RNN虽然理论上可以很漂亮的解决序列数据的训练,但是它也像DNN一样有梯度消失时的问题,当序列很长的时候问题尤其严重。
同时,随着序列加长,模型很难捕捉前面的输入与后面的输入之间的关系,举个例子,我有两句话
$$The \ person, \ who \ standing \ there\ and……, \ is \ lively.$$
$$The \ people, \ who \ standing\ there\ and……, \ are \ lively.$$
除了主语的单复数之外,其他的成分一模一样,而且在主谓之间,有一句可以无限长的从句,这种情况下,模型在判断后面到底是is还是are的时候,就非常困难。一方面存在梯度爆炸或者梯度消失问题,另一方面,主谓之间的依赖性(就是 $a^{ < i > }$ )会随着从句的边长而被稀释。
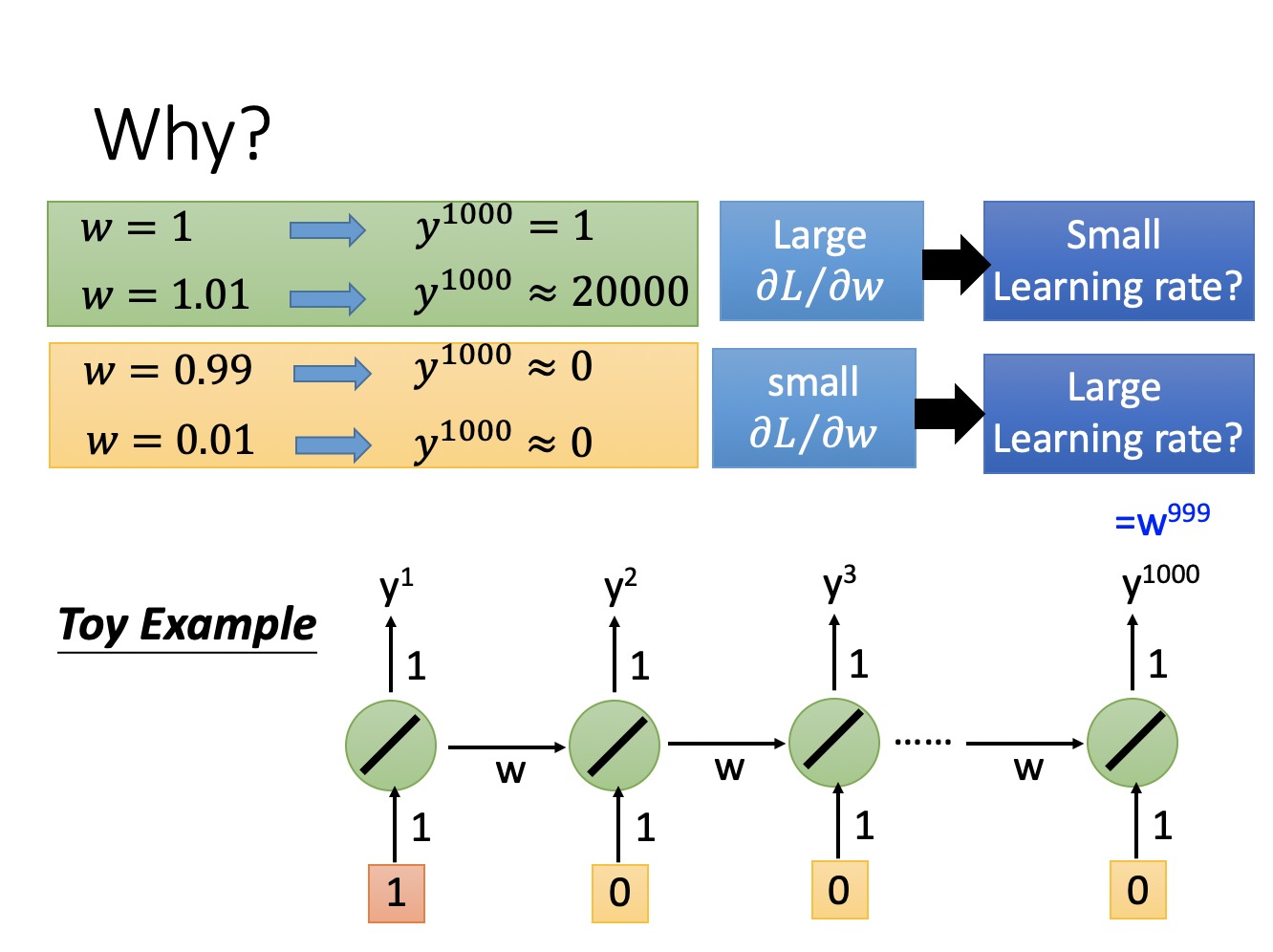
因此,上面的RNN模型一般不能直接用于应用领域。在语音识别,手写书别以及机器翻译等NLP领域实际应用比较广泛的是基于RNN模型的一个特例LSTM,下面我们就来讨论LSTM模型。
长短时记忆模型(Long Short-Term Memory LSTM)
【Colah】Understanding LSTM Networks
【李宏毅】机器学习-Recurrent Neural Network(2019)
概述
原始RNN模型只有一个计算流程,$x^{< t >} \rightarrow a^{< t >} \rightarrow y^{< t >}$,如下图所示。
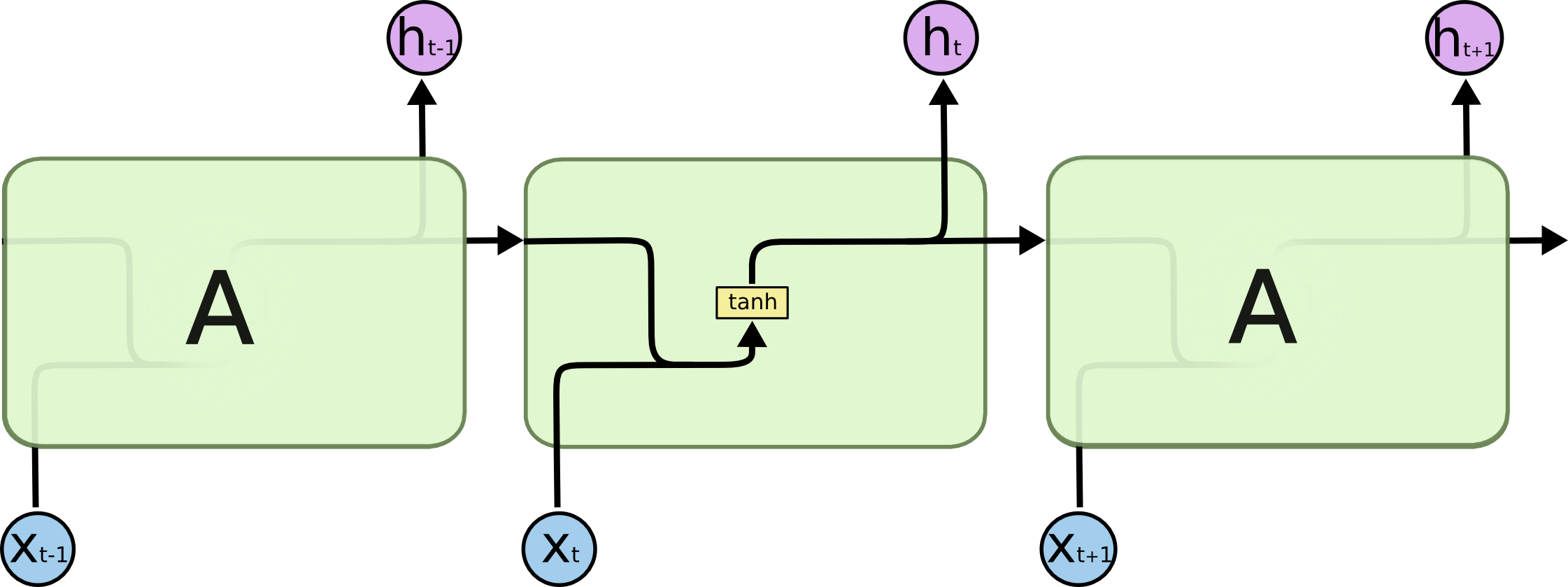
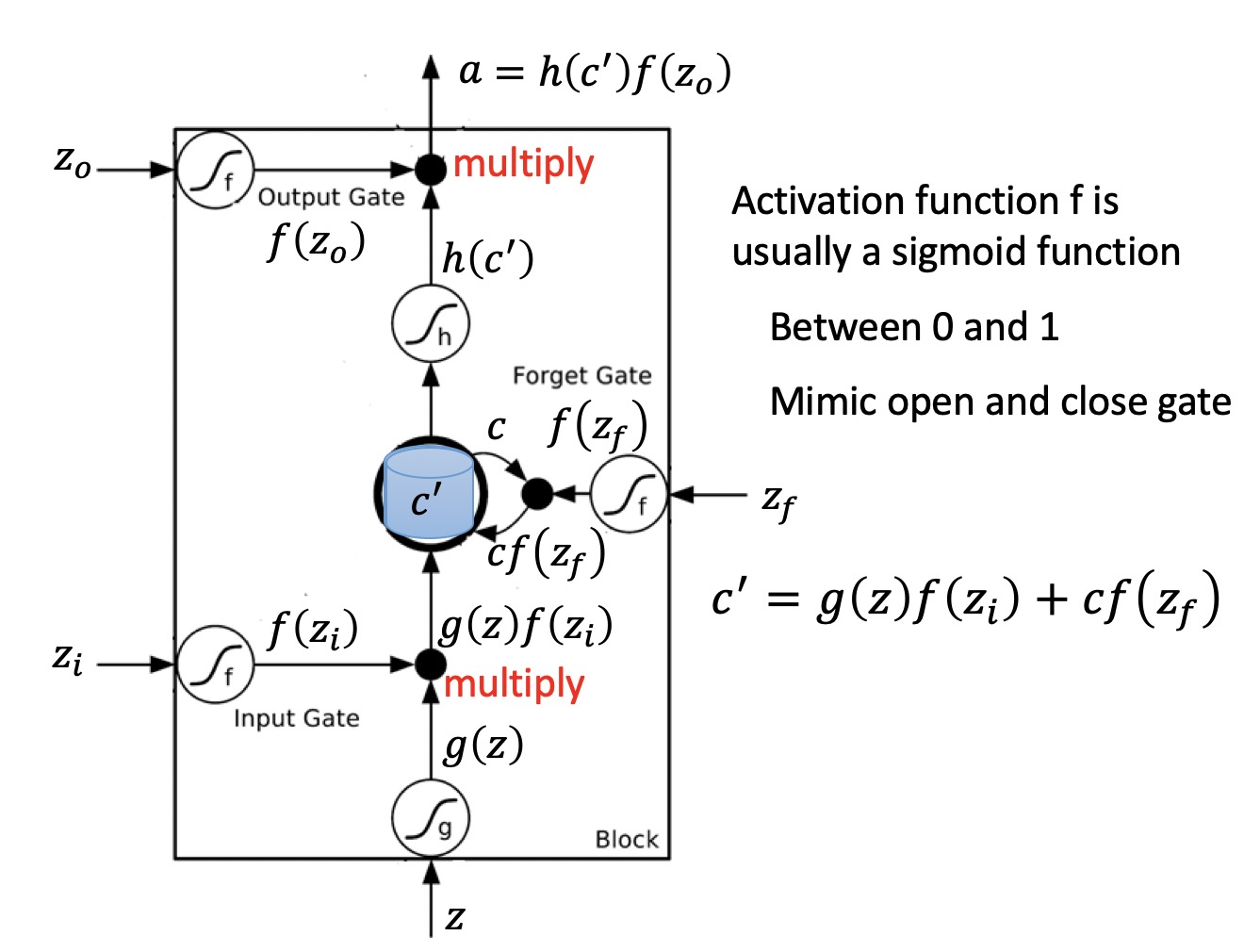
而LSTM则增加了三个计算流程,如下图。
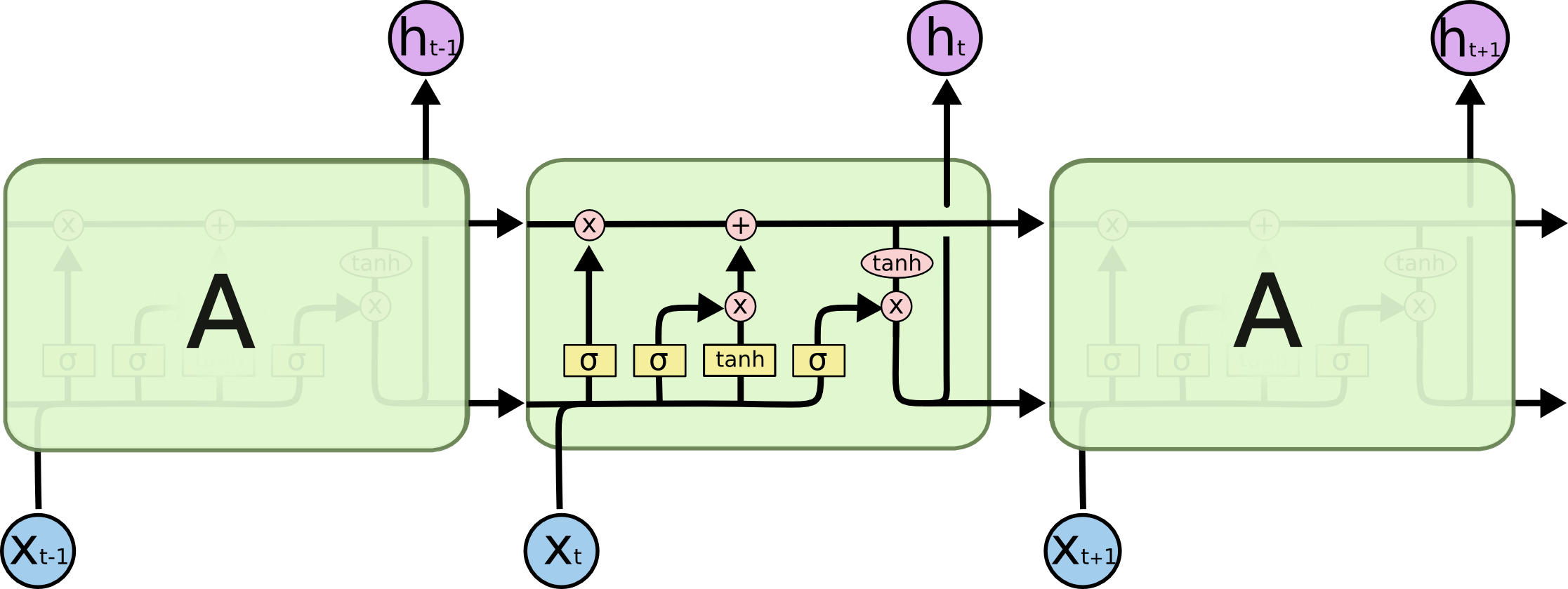
这几个流程是什么意思呢?
LSTM的本质,其实就是对$a^{< t >}$的一系列改进,也就是对输入$x^{< t >}$状态的改进。
更形象地说,还是那两句话:
$$The \ person, \ who \ standing \ there\ and……, \ is \ lively.$$
$$The \ people, \ who \ standing\ there\ and……, \ are \ lively.$$
我的目的就是,即使主谓之间隔着这么远的距离,我仍然能够让计算机知道,后面的谓语应该是单数还是复数,LSTM实际上就是通过增强了$a^{< t >}$对$a^{< t + i>}$的影响,来增加$x^{< t >}$对$x^{< t+i >}$的影响。
这种影响的增强,就是通过的三个门来实现的。
- 输入门
保留多少 当前时刻输入 到 当前时刻单元状态。
- 遗忘门
保留多少 前一时刻单元状态 到 当前时刻单元状态。
- 输出门
保留多少 当前时刻单元状态 留给 下一时刻的单元状态。
下面我们一步步详述。
门机制
遗忘门
首先,我需要利用上一个输入量得到的输出为参考量,去判断上一个单元状态对现在的输入量,有多少联系。
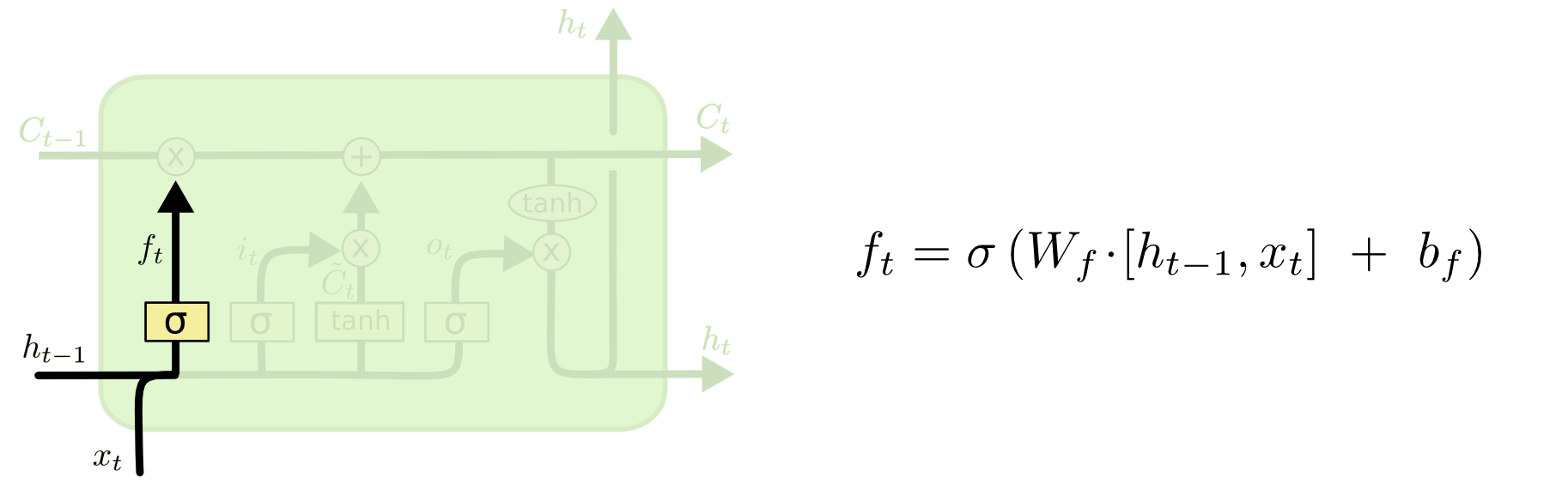
这个$f_t$是一个尺度,在0-1之间,用来度量上一个单元状态对此刻单元状态的约束。
输入门
然后,我要判断,当前输入量有没有价值,是否需要把它存到我的单元状态里面。
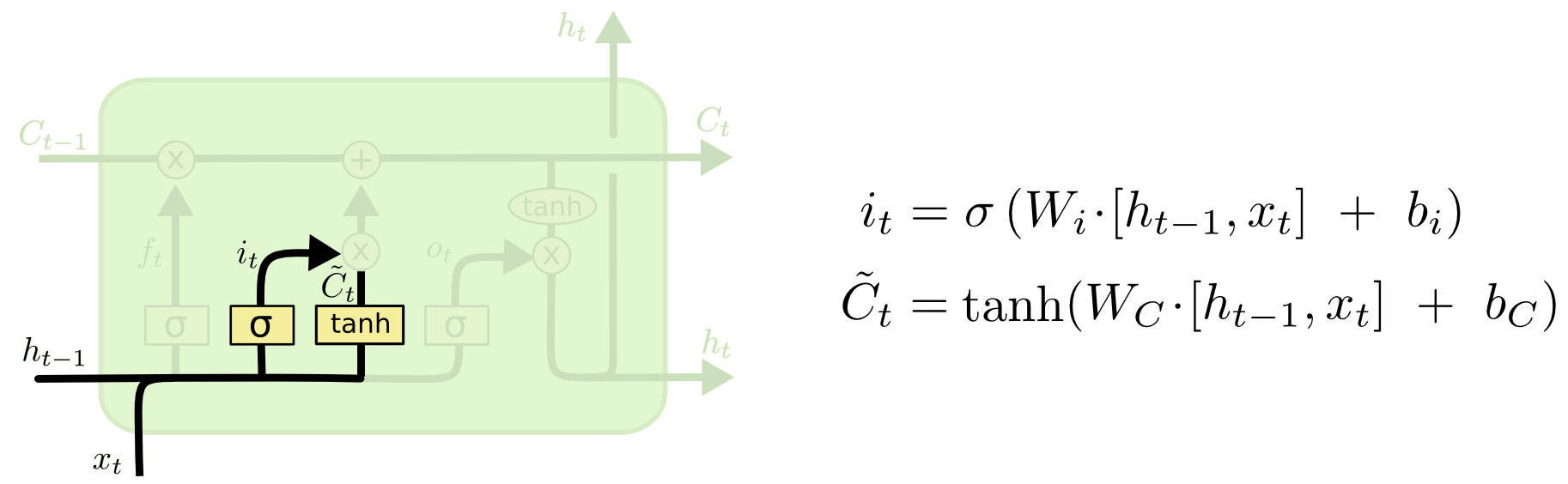
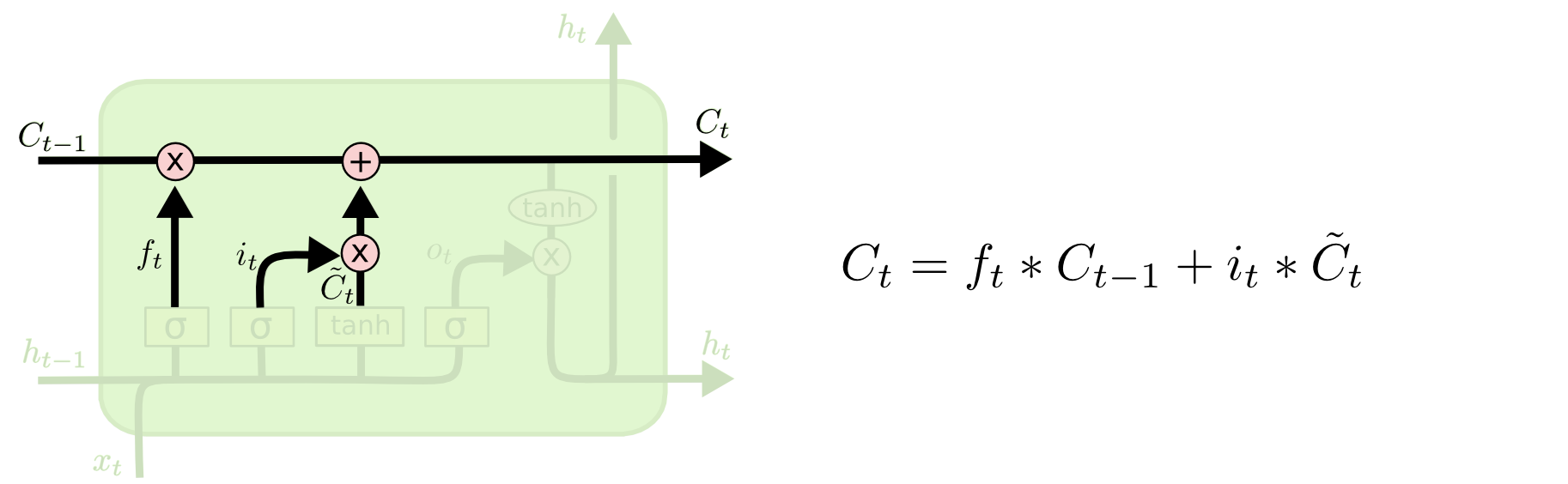
再然后,我综合通过遗忘门和输入门的值,得到了当前单元状态量。这个单元状态量,结合了前一个输出量与现在输入量的综合关系。
输出门
最后,我需要一个尺度,来判断我算出来单元状态量有多少意义,这个尺度就是输出门。
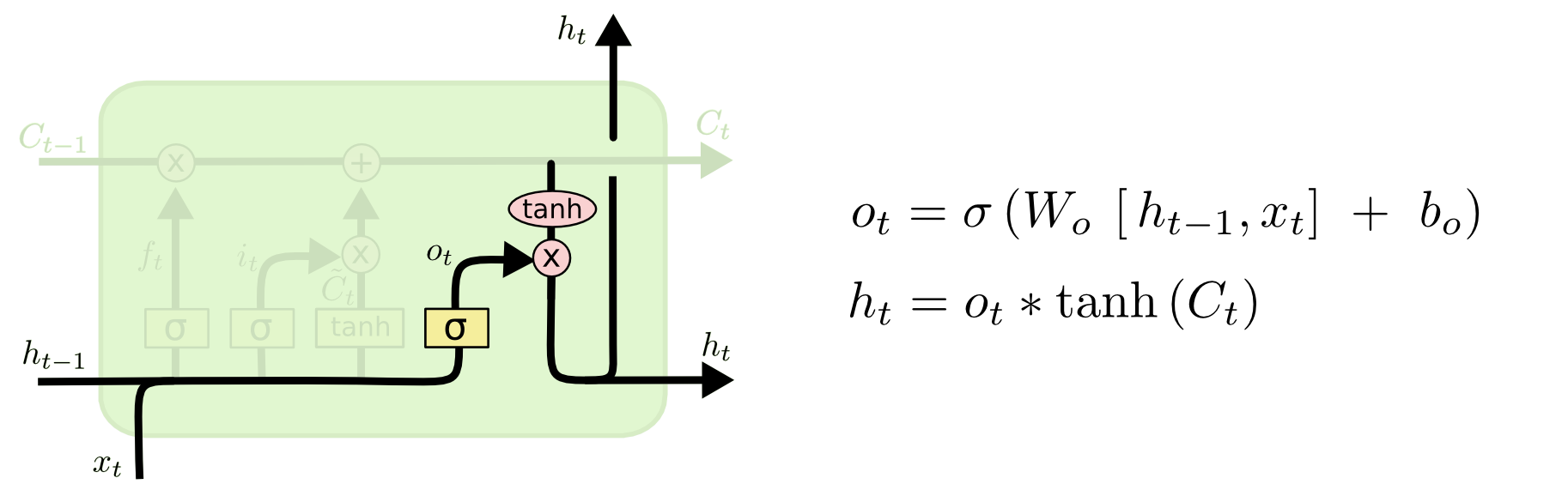
总结以上叙述,整个流程可以归纳为:
- 通过输入门,得到当前时刻输入值的对当前单元状态的价值;
- 通过遗忘门,得到前一时刻单元状态对当前单元状态的价值;
- 累加1、2两步的值,得到的当前单元状态,表示的意义为:当前输入值和上一输入值对当前状态的意义;
- 通过输出门,得到当前状态值对输出结果的影响。
整个过程可以跟着上图过一遍。
生成对抗网络(Generative Adversarial Networks)
强化学习方法:策略梯度(Policy Gradient)
该方法可参考我以前的学习笔记,【强化学习】Policy Gradient
写得还算详细,故此不再赘述。
实现思路/逻辑
LTSM
GAN+PG/GAN+RL
实现细节/代码
LTSM
GAN+PG/GAN+RL
Reference
【Karpathy】The Unreasonable Effectiveness of Recurrent Neural Networks
【Colah】Understanding LSTM Networks
【李宏毅】机器学习-Recurrent Neural Network(2019)


- 本文作者: YA
- 本文链接: https://shiyuang-scu.github.io/2019/03/11/GAN-RL-文本生成的方法/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!