
对几篇半监督学习经典论文的粗读。
这一派的核心思想就是,利用无标签的数据,来对模型基于有标签数据的训练,进行约束。相当于一个对模型正则化的过程,来降低模型的过拟合问题。(之所以认为这样做是有用的,是基于低密度假设。就是decision boundary经过的区域是低密度的,数据分布在远离decision boundary的地方。因此随机扰动不会改变数据的label,也就是不会cross boundary。如下图)
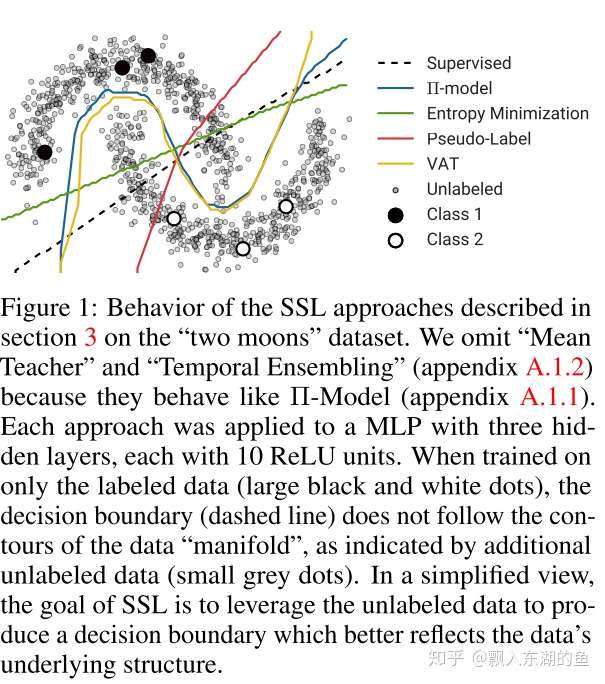
1 Pseudo-label [1]
直接把无标签数据当成有标签数据,无标签数据的标签看其输出(比如输出是0.6,那么标签就是1,输出是0.1,标签就是0)。直观上是说,是pseudo-label与概率的一致性,
然而,这样简单粗暴地定义无标签数据的标签,肯定会给模型学习带来很大问题,因为很容易标错啊。所以以后的工作,其实本质上就是对这个问题的改进
2 Temporal ensembling [2]
1)pi-model[2]: (前要知识:每一次跑模型,都会随机变一个数据扰动)每次计算两次无标签数据的预测值,目的是让两个经过不同数据扰动后的无标签数据的结果变得一样。直观上是说,是同一样本不同扰动后结果的一致性。
2)temporal ensembling[2]: (前要知识:每一次跑模型,都会随机变一个数据扰动)对pi-model的改进,本质上是一样的。不用计算两次,而是当前的结果与之前结果进行比较。Zi‘由之前一段时间得到的Z指数移动平均得到,Zi由本来自当前迭代时间内产生。直观上说,Zi‘相当于对之前的所有数据扰动做一个平均。
这个工作直接把无标签样本的分类损失定义为“一致性损失”,就是说不像上一个工作一样,把标签和预测值的差距作为损失,而是避开它,计算同一个样本经过不同数据扰动后的不同结果间的一致性。
3 mean teacher[3]
(前要知识:每一次跑模型,都会随机变一个数据扰动)这个模型里有两个网络:student和teacher。student模型是正宗的模型,teacher对student起约束和正则化作用。在训练过程中,teacher的参数是student参数的指数平均。
与上一个工作核心思想一样,只是就性能上进行了改善,其实是一个性能改进罢了,但是idea很新颖有趣。上一个工作计算同一个样本经过不同数据扰动后的不同结果间的一致性,但是temporal ensembling算起来很慢,在online情况下没法用。所以这个工作干脆直接改模型参数,在每一次更新student模型参数之后,取指数平均,作为teacher模型的参数。然后再计算同一个样本在这两个模型的不同结果之间的一致性。对参数的指数平均,内在的意思,其实就是和上一个工作让Zi‘取之前结果的指数平均,一样。
Reference
[1] Lee, Dong-Hyun. “Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks.” Workshop on challenges in representation learning, ICML. Vol. 3. No. 2. 2013.
[2] Laine, Samuli and Aila, Timo. ”Temporal ensembling for semi-supervised learning.“ In Fifth International Conference on Learning Representations, ICLR 2017.
[3] Tarvainen, Antti and Valpola, Harri. “Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.” Advances in Neural Information Processing Systems,NeuIPS 2017.
https://zhuanlan.zhihu.com/p/99513085
https://zhuanlan.zhihu.com/p/179233410


- 本文作者: YA
- 本文链接: https://shiyuang-scu.github.io/2021/06/07/半监督学习-论文粗读/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!