
引言
本文简单介绍了视频压缩的基本原理,对视频编码解码进行了概述。内容基本上就是复述了一遍这份文档: introduction to video technology,使用的图片也大部分来源于此。
之所以重复造了一遍轮子,是因为我觉得这份学习资料非常清晰明了地介绍了视频压缩的基本概念和方法,一方面想通过费曼教学法的方式,让自己对这些内容有更深的理解,另一方面也想借着这份漂亮的文档,把敝博客弄得技术一点。😅
背景知识&术语介绍
思维导图如下。
一张图片可以被视为一个矩阵,矩阵里的element被称为像素(pixel),像素是图片最小的组成单位。
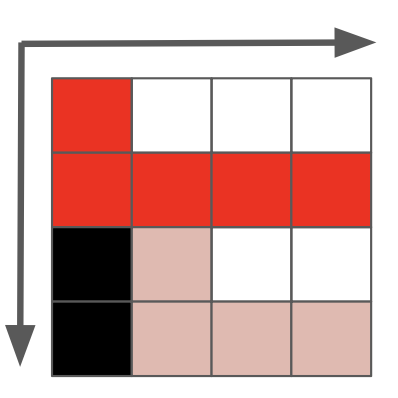
每一个像素都有自己的位置、颜色,如果我们用三原色(红色、绿色、蓝色,RGB)来表示颜色,那么像素的颜色就由三原色的强度(通常用数值表示)表示,其中三原色的强度范围是0-255。
RGB只是其中一个颜色模型,另外还有很多颜色模型比如YCbCr、HSL、HSV等等,RGB只是相对来说运用最广泛的颜色模型。
存储颜色的强度,需要占用一定大小的数据空间,这个大小被称为颜色深度 (color / bit depth)。对于RGB颜色模型来说,每个原色的强度取值范围是0-255,即占用 8 bit,那么颜色深度就是 24(8*3)bit,由此也可以知道RGB颜色模型可以表示最多2 的 24 次方种不同的颜色。
图片是有大小之分的,图片越大,像素越多,那么能传达的信息也越精细,我们把一张图片内像素的数量称为分辨率(resolution)。
除了大小以外,图片的宽高比也是一种属性,它简单地描述了图像或像素的宽度和高度之间的比例关系。一张图片有宽高比,我们称为显示宽高比(display aspect ratio,DAR),一个像素也有宽高比,我们称为像素宽高比(pixel aspect ratio,PAR)。
一个视频由一系列连续的图片组成,每一个图片称之为帧(frame)。一张图片是一个三维的矩阵,视频则多加了一个时间维度,因此是四维的矩阵。
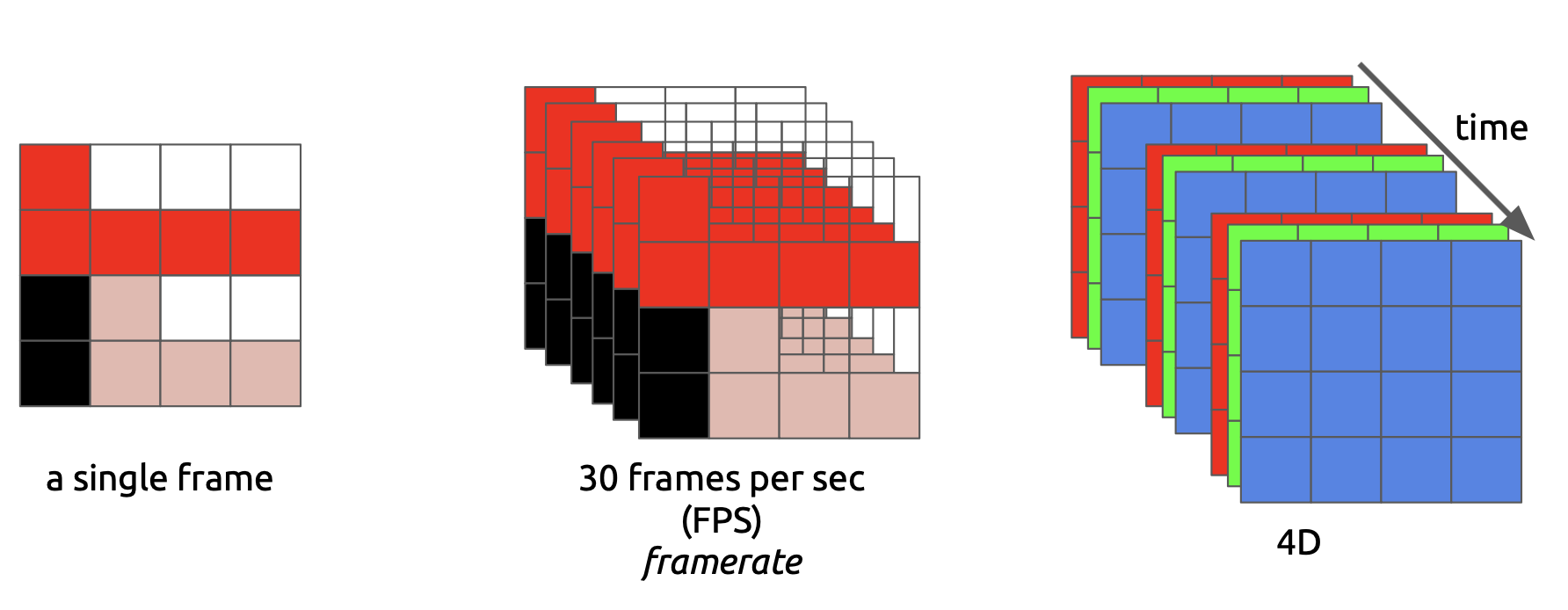
帧率是指视频在单位时间内连续的 n 帧,若单位时间为秒,则称之为 FPS (每秒帧数 Frames Per Second)。帧率越高,视频看起来越流畅,人眼越难分辨离散图像之间的停顿。
播放一段视频每秒所需的数据量就是它的比特率(bitrate),即常说的码率。
$$bitrate = width \times height \times bit depth \times FPS$$
如果一个视频的比特率是恒定的,那么我们称之为恒定比特率(constant bitrate,CBR),如果是变化的,那么称之为可变比特率(variable bitrate,VBR)。之所以会存在可变比特率,是因为一般来说一个视频里会有很多帧不需要太高的比特率,比如说一个在黑夜里拍摄的视频,全黑的图像只需要用很低的比特率。利用可变比特率,就可以减少视频的大小。
在早期,工程师们想出了一项技术能将视频的感官帧率加倍而没有消耗额外带宽。这项技术被称为隔行扫描 (interlaced scan);总的来说,它在一个时间点发送一个画面——画面用于填充屏幕的一半,而下一个时间点发送的画面用于填充屏幕的另一半。如今的屏幕渲染大多使用逐行扫描(progressive scan)。这是一种显示、存储、传输运动图像的方法,每帧中的所有行都会被依次绘制。我们经常看到的1080p和1080i,p和i指的就是逐行扫描和隔行扫描。
视频压缩的基本原理——消除冗余
现在我们有一段视频,这一段视频每秒 30 帧,每个像素占 24 bits大小,分辨率是 480x240,如果我们不做任何压缩,它将需要 30x480x240x24=82,944,000 比特每秒 (bps) 或 82.944 Mbps。如果这是一个一小时长的视频,分辨率为 720p 和 30fps, 那么这个视频就需要 278GB(1280 x 720 x 24 x 30 x 3600 (宽,高,每像素比特数,fps 和秒数))。
因此,我们必须要对视频进行压缩,而视频压缩的关键在于消除冗余。消除冗余主要有三点:(1)视觉特性:相比颜色,我们对亮度要敏感得多;(2)时间上的重复:一段视频包含很多只有一点小小改变的图像;(3)图像内的重复:每一帧也包含很多颜色相同或相似的区域。
人类视觉系统的基本原理
首先,我们的眼睛对亮度和颜色是分开处理的,其中,视杆细胞主要负责亮度,而视锥细胞负责颜色,有三种类型的视锥,每个都有不同的颜料,叫做:S-视锥(蓝色),M-视锥(绿色)和L-视锥(红色)。其次,眼睛有大约1.2亿个视杆细胞和6百万个视锥细胞,处理亮度的细胞比处理颜色的细胞要多得多,因此,一个合理的猜测是,相比颜色,我们有更好的能力去区分黑暗和光亮,各种实验也证明了这个猜测。
之前提过,RGB颜色模型把颜色分离成红色、绿色和蓝色,所有颜色都可以用三原色组成,此外还有很多颜色模型进行了不同的分离。我们这里主要谈论YCbCr模型,YCbCr把颜色分离成亮度(Y)、蓝色色度(Cb)和红色色度(Cr)。YCbCr 与 RGB可以互相转换。
现在,我们知道人类视觉系统对亮度比色度更敏感的特点,而且我们建立了一个颜色模型,能够分离亮度和色度。因此,我们就可以降低颜色的分辨率,保持亮度的分辨率,来减少图像的大小。色度下采样(Chroma subsampling)就是一种编码图像时使色度分辨率低于亮度的技术。
已经有一套标准,来规范把色度分辨率降低到何种程度。这些标准称为下采样系统,并被表示为 3 部分的比率 - a:x:y,其定义了色度平面的分辨率,与亮度平面上的、分辨率为 a x 2 的小块之间的关系。
a是水平采样参考 (通常是 4),x是第一行的色度样本数(相对于 a 的水平分辨率),y是第二行的色度样本数。
现代编解码器中常用的方案是: 4:4:4 (没有下采样), 4:2:2, 4:2:0, 4:1:1。

相比4:4:4(没有下采样),使用4:2:2模式只需要二分之三的数据,使用4:2:0则只需要二分之一的数据。如果使用4:2:0,一个1小时长、分辨率为 720p、30fps的视频的大小就从 278GB 缩小到了 139 GB,但是,仍然非常大。
时间与空间冗余
基本术语
在谈论消除时间冗余之前,先确定一些基本的概念。
下图是连续的四帧吃豆人图像。可以看到这四帧的大部分内容是相同的:白色的背景,黄色的吃豆人,只有豆子在变化。

为了方便描述减少冗余的算法,我们将它们抽象地分类为三种类型的帧。
- I 帧 (key frame,intra)。I 帧也被称为关键帧,这一帧是一个reference frame。
- P 帧 (predicted)。我们可以通过上面的例子看到,当前的图像几乎和前一帧一样,因此总能使用之前的一帧进行重建。例如,在第二帧,唯一的改变是豆子向前移动了。因此,我们只需要知道第一帧(I 帧),和第二帧和第一帧的差值,就能重建第二帧,第二帧被称为P 帧。
- B 帧 (bi-predicted)。除了利用当前帧和前一帧的时间冗余,我们也可以同时利用当前帧和后一帧的时间冗余。例如上图,第三帧相对于第二帧,豆子向前移动的同时,还多了一颗,第三帧相对于第四帧,豆子只是向前移动。因此,我们只需要存储第三帧和第二帧、第四帧的差值即可,进一步减少了需要存储的数据量。
时间冗余
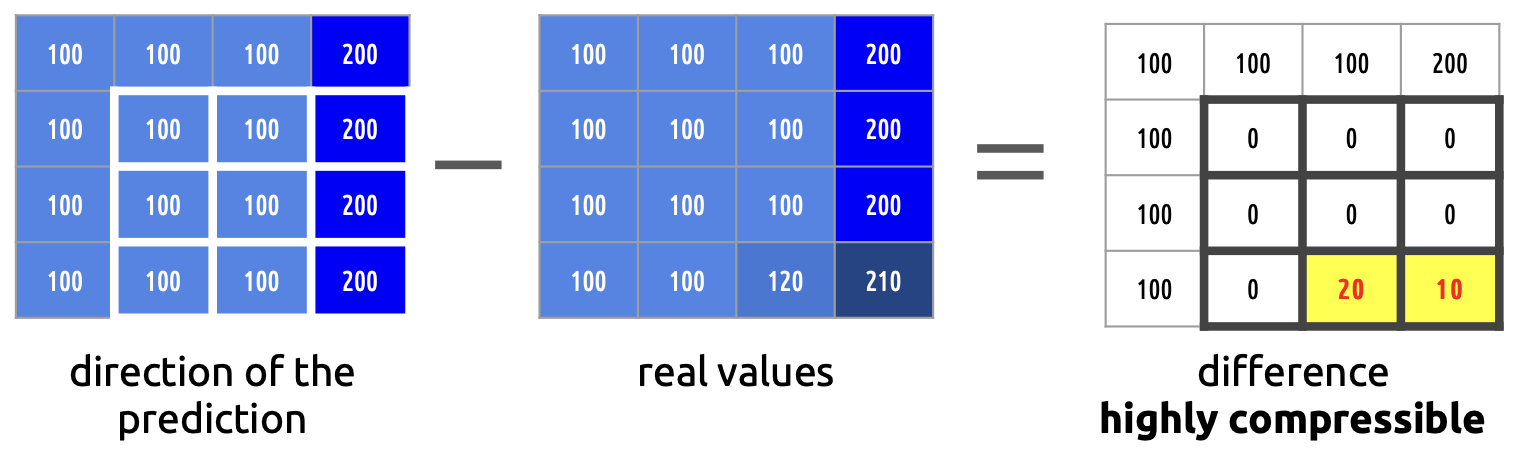
首先,需要明确的是,连续帧之间存在时间冗余。一般的视频是30帧每秒,每2帧之间只相差1/30秒,因此,连续帧之间的内容几乎是不变的。我们不需要原原本本地存储连续几帧,我们只要知道这些帧之间的相对变化就好了,比如说,我只要存储第一帧,以及第二帧和第一帧的差值,就能还原第二帧。
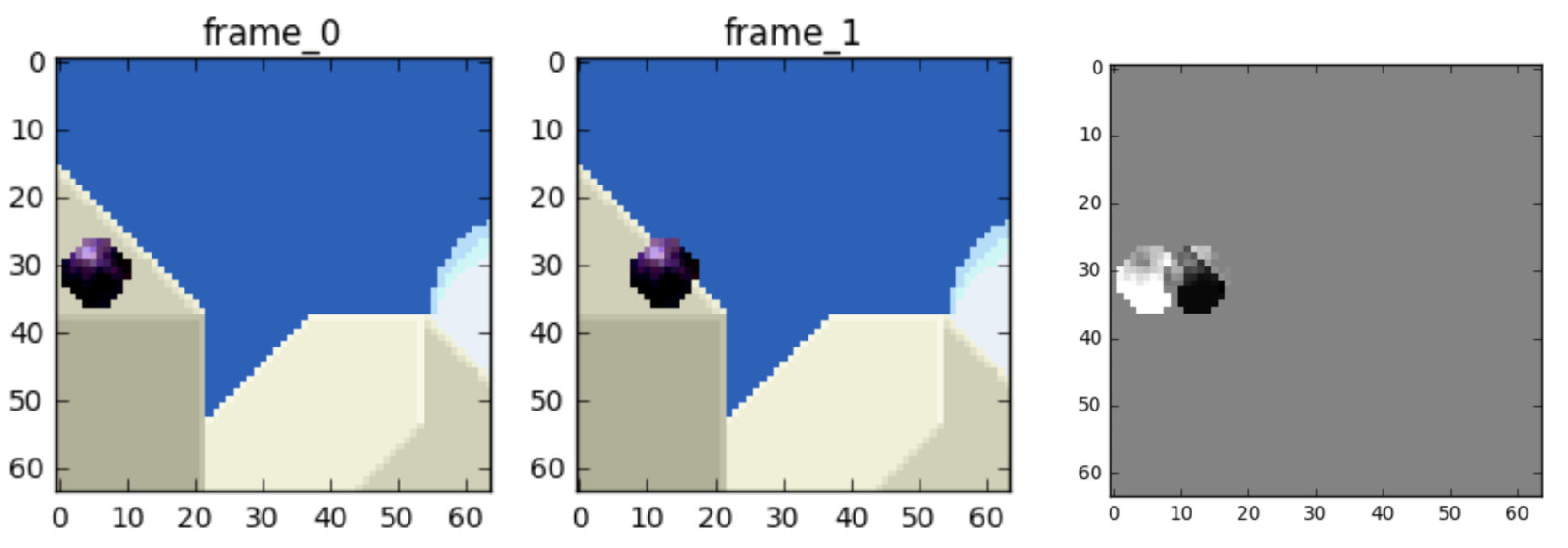
以上图为例,从左到右分别是frame 0、frame1、两者的差值,我们只需要存储frame 0和差值,就能还原frame 1,这样就极大地减少了数据量。
但是,我们还可以进一步压缩数据量,使用的技术叫做motion estimation & motion compensation,运动预测和运动补偿。
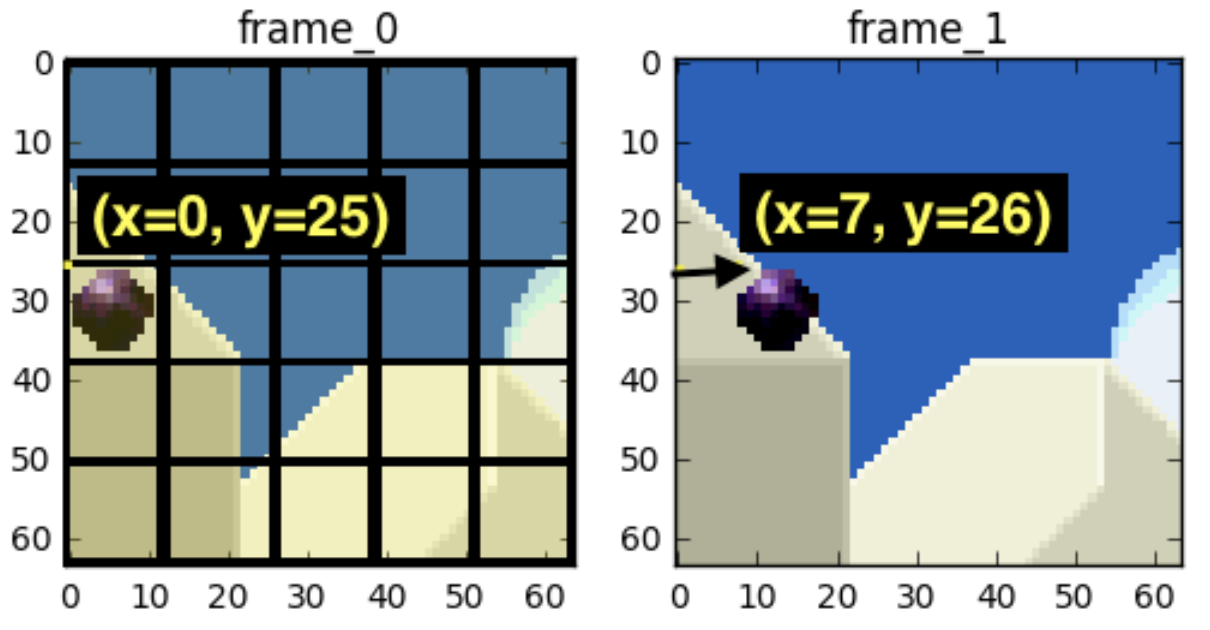
简单地说,首先,我们把一帧分成小块,然后估计前一帧里每一个小块是怎样移动到当前帧中的某个位置去。如下图所示,我们预计那个球会从 x=0, y=25 移动到 x=6, y=26,x 和 y 的值就是运动向量(motion vector)。这一步称为motion estimation。
然后,我们就可以利用前一帧和预测的运动向量,来重建当前帧。这一步称为motion compensation。
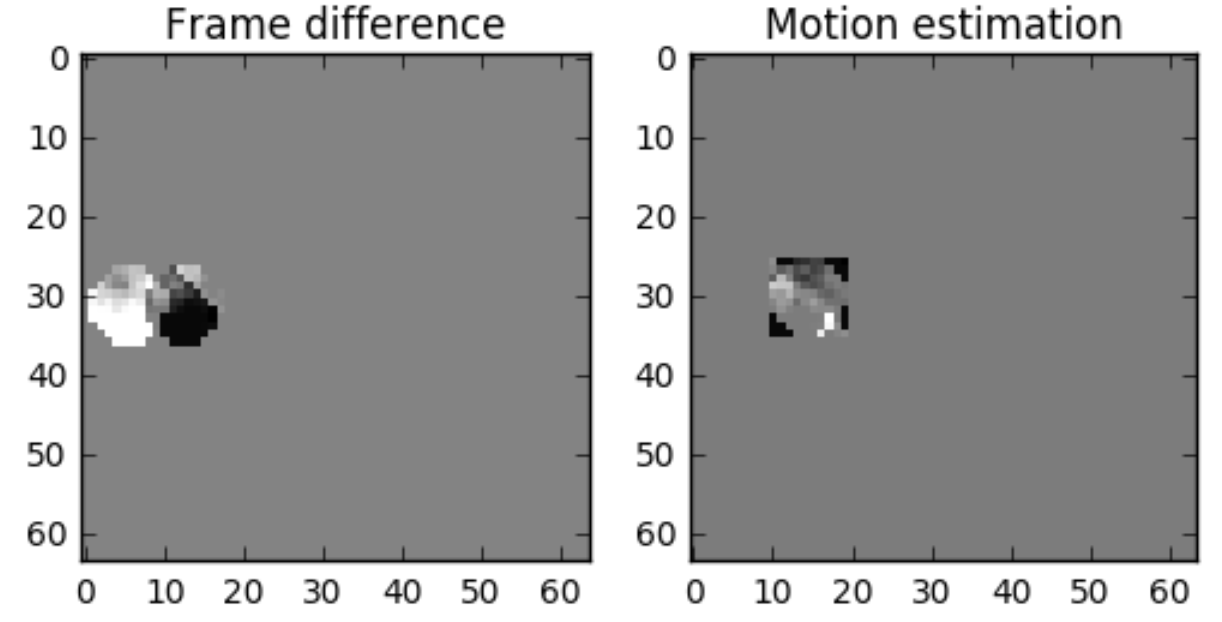
预测肯定是不准的,因此,我们还需要计算重建帧与实际帧的差值。即便如此,使用motion estimation时,数据量仍然少于使用简单的残差帧技术。如下图所示。
空间冗余
上一节讨论了如何利用帧与帧之间的时间相关性,来消除冗余。具体地说,我们通过motion estimation & motion compensation,极大地减少了P 帧和B 帧的数据量。然而,我们仍然需要原原本本地存储I 帧。这一节将介绍如何利用像素与像素之间的空间相关性,来进一步压缩I 帧。
我们可以发现,在视频的每一帧里,有很多区域是相似的,一般来说,一个像素通常与它相邻的像素们相似,这被称之为空间相关性。因此,只要知道相邻区域的颜色变化,就能估计出当前区域的颜色变化。
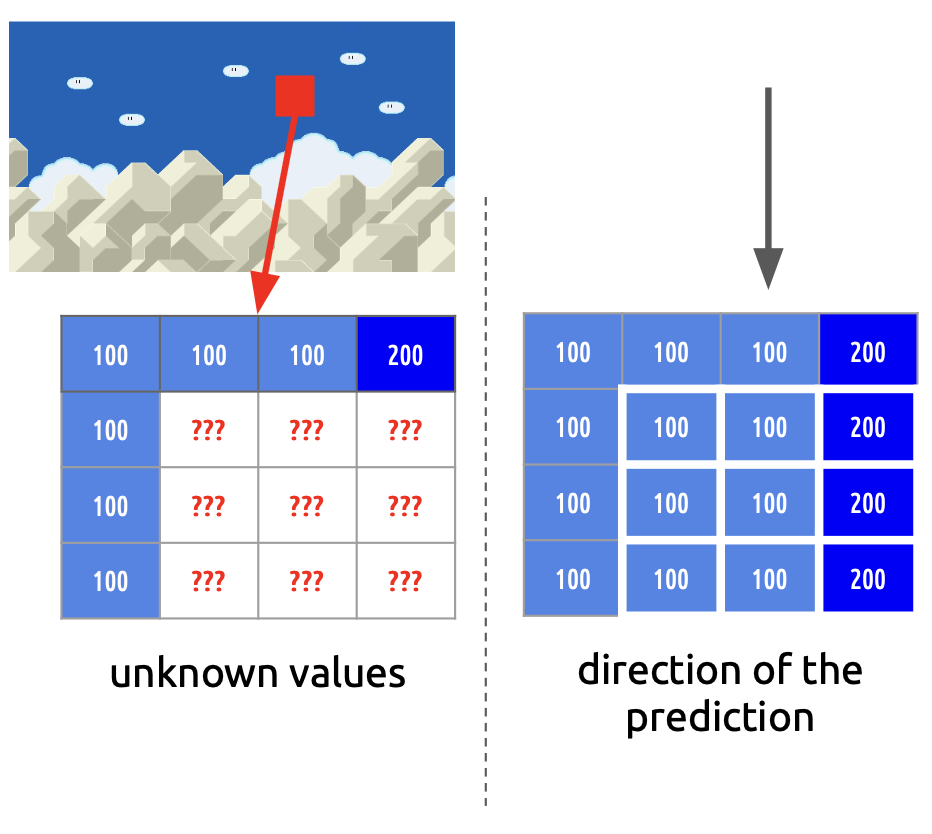
以下图左图为例,我们有一张图片,我们想要预测红色区域的颜色,同时我们知道这个红色区域周围的颜色。我们假设红色区域的颜色在垂直方向上与其邻近区域是一样的(有很多更好的颜色预测方法,这里只是用了一个简单的例子),那么我们就能得到一个颜色估计,如下图右图所示。
同样的,我们的预测肯定不是完美的,因此我们还会减去实际值,算出残差,如下图所示。我们只需要存储残差以及邻近区域的颜色,就能得到该区域的颜色。可以看出,通过这个方法,我们进一步极大地减少了需要存储的数据量。
视频编码解码器(codec)
引言
上一部分介绍了视频压缩的基本原理,包括利用人眼对亮度更敏感消除色度的冗余,利用视频时间相关性和空间相关性消除冗余。这一部分将会介绍视频编码解码器的主要工作机制。
根据维基百科,Codec(Encoder/Decoder)是用于压缩或解压数字视频的软件或硬件(A codec is a device or computer program for encoding or decoding a digital data stream or signal)。Codec的核心想法就是如上节所述的,利用人眼视觉的特点、视频的时间空间相关性来消除冗余,另外在这几个核心想法的基础上,做一些修修补补,尽一切所能来压缩数据。
结构概览
大部分codec都拥有相似的流程,如下所示。首先是图片分区,把一张图片分割成一个个小块,以便于后面更准确的motion estimation和compensation。第二,利用时间、空间相关性,来消除帧间、帧内的冗余,做了这些处理后,一张张图片变成了一张张残差块。第三,对得到的残差块进行进一步的处理,使得空间冗余进一步压缩。第四,对转换后得到的结果再做一步处理,有损地剔除信息,使得结果更容易被编码压缩。最后,利用编码技术,把量化后的数据用更少的数据表示出来。

可以看到,最重要的步骤是prediction,prediction后面的三步都是对prediction得到的数字进行各种转化、处理,来进一步压缩数据罢了。
第一步:图片分区 (picture partitioning)
第一步是将帧分割成小块。把图片分割成小块的原因是,粒度越小,motion estimation就越准确,然而问题是,分割的区块越小,所需要的计算量也越大。因此,当我们分割图片时,我们一般可以在有变化的部分使用较小的分区,在静态的部分使用较大的分区(基于这个想法,肯定存在更高级的方法来更好的分区,但是我因为懒,没有做调查)。
第二步:预测 (prediction)
我们在前几节提过了利用motion estimation&compensation来利用时间相关性消除帧间的冗余,和利用空间相关性消除帧内的冗余,因此在此就不赘述了。对于帧间预测,我们需要发送运动向量和残差;至于帧内预测,我们需要发送预测方向和残差。
第三步:转换 (transformation)
在得到了残差块之后,下面的几步就都是对残差块进行各种数值变换,来发现某些特征,然后再利用这些特征进行压缩。
这里主要介绍一下离散余弦变换(DCT)。DCT 的主要功能有:
- 将像素块转换为相同大小的频率系数块。
- 压缩能量,更容易消除空间冗余。
- 可逆的,也意味着你可以还原回像素。
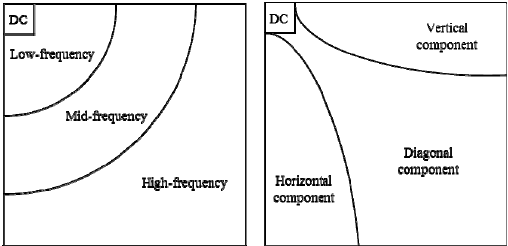
简单来说,我们将图片视为信号,通过DCT的一系列变换,图片能够被转换成一个频率系数块(frequency coefficient),如下所示。在这个系数块中,被视为信号的图片,它的低频和高频部分被分离了,其中,左上角是低频部分,右下角是高频部分。需要知道的是,在一张图像中,大多数能量会集中在低频部分,所以如果我们将图像转换成频率系数,并丢掉高频系数,我们就能减少描述图像所需的数据量,而不会牺牲太多的图像质量。
因此,在得到一个频率系数块后,我们可以舍弃一些高频部分保留低频部分,然后再把这个频率系数块还原成像素。
举个例子,在我们得到一个频率系数块后,我们直接舍弃67%的高频部分,然后再把这个舍弃掉67%高频部分的系数块还原成像素。如下图所示,左边是原始的图片,右图是丢弃了67%高频部分后还原的图片,我们可以看到,即使丢弃了 67% 的信息,图片仍然保留了基本的信息。(当然,肯定有更聪明的方法来丢弃频率系数块里相对没用的部分,但是因为我懒,所以没有做调查)
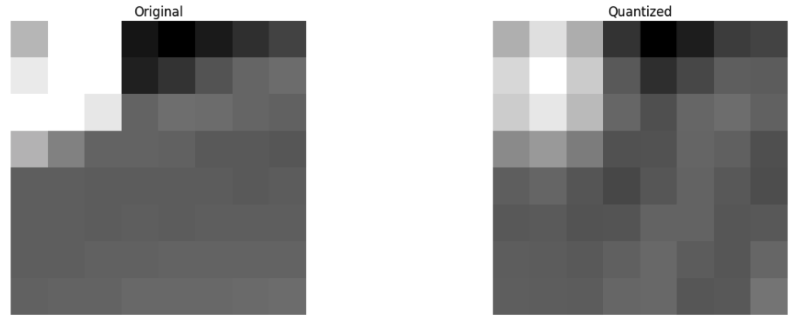
在经过prediction、transformation之后,我们得到了一个丢弃了高频部分的频率系数块。回想一下,我们先是把一系列图片通过prediction变成了一系列残差块(数据量大幅变少);然后再把这些残差块进行DCT,变成了频率系数块,然后丢弃掉相对没用的部分(高频部分),进一步减少了数据量。接下来,我们就要对这个剔除了高频部分的频率系数块进行处理,让它的数据量变得更加少。简单来说,就是压缩频率系数块,而接下来两步就是为了完成这个使命。
第四步:量化 (quantization)
在计算机里,数据都是用二进制来表示的。比如说,255用二进制来表示就是11111111,需要用8个bit表示,25则是11001,需要5个bit表示。那么,我们很自然地就想到,我们能不能把数据全部限制在一个比较小的范围内,这样就可以用比较少的bit来表示所有数据。比如说,原来的数据范围在0-255,每个数据需要用8个bit来存储,那么现在我把所有数据都限制在0-15,每个数据就只需要用4个bit来存储,数据量整整少了一半。
这就是quantization的核心想法。我们如何量化一个系数块?一个简单的例子是均匀量化,我们取一个块并将其除以单个的值(比如说10),并向下取整,如下图所示。
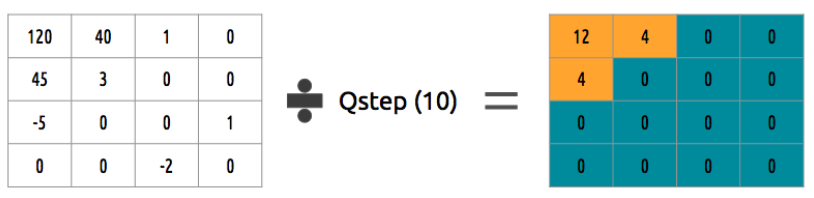
这样一来,我们的数据范围就从-5到120变成了0到12。要还原到原来的系数块,重新乘以10就可以了。这个方法很简单,同样的,肯定有更聪明的方法来对系数块进行量化,但是因为我懒,所以没有做调查。
我们可以使用一个量化矩阵来代替单个值,这个矩阵可以利用 DCT 的属性,多量化右下部,而少(量化)左上部,JPEG 使用了类似的方法,你可以通过查看源码看看这个矩阵。
我们可以注意到,这个操作是有损压缩,还原的数据和原先的数据是不一样的,而且再也没办法还原到原先的数据了。
第五步:熵编码 (entropy coding)
现在,我们量化了数据,数据量变得更少了。但是,我们还可以进一步压缩。
之前举了一个例子,如果我把所有数据的范围从0-255缩小到0-15,每个数据就只需要用4个bit而不是8个bit来存储,数据量整整少了一半。但是,数据的分布是不均匀的,比如我有一个量化后的系数块,其中只有1个数值是15,其他全是1,那么实际上我不需要用4个bit来存储这些数据,我只需要用1个bit就可以了,0表示15,1表示1。我只需要存储这个一一对应关系的字典,就可以无损地还原它们。
entropy coding的基本想法就是这样,利用统计特征来重新编码数据。用许多方法来重新编码数据,下面简单介绍1种方法:VLC(Variable-length code)编码。当然啦,还有非常多更聪明的编码方法来压缩数据量,但是因为我懒,所以没有做调查。
VLC编码
现在我们有一个符号流:a, e, r 和 t,经统计,它们出现的概率(从0到1)由下表所示。
| a | e | r | t | |
|---|---|---|---|---|
| 概率 | 0.3 | 0.3 | 0.2 | 0.2 |
一个很自然的想法是,我们可以分配不同的二进制码,把小的二进制码给最可能出现的字符,把大些的二进制码给最少可能出现的字符,如下表所示。
| a | e | r | t | |
|---|---|---|---|---|
| 概率 | 0.3 | 0.3 | 0.2 | 0.2 |
| 二进制码 | 0 | 10 | 110 | 1110 |
现在我们想压缩 eat 这个单词,假设我们为每个字符花费 8 bit,在没有做任何压缩时我们将花费 24 bit。但是在这种情况下,我们使用各自的代码来替换每个字符,我们就能节省空间。根据上表的结论, e 的二进制码是 10,第二个字符 a 的二进制码是 0,第三个字符 t 的二进制码是 1110,最终组成已压缩的比特流是 1001110,这只需 7 bit(比原来的空间少 3.4 倍)。
一般使用Huffman编码来找到每个符号对应的二进制码。
第六步:比特流格式 (bitstream format)
回顾一下,我们先是利用视频的时间相关性和图片的空间相关性,消除了冗余;然后,我们对残差块进行了DCT转换、量化、熵编码,用信号处理理论和编码理论,再一次狠狠地压缩了数据。到此,压缩就告一段落了。
接下来的问题是,我们在得到了压缩后的数据,以及恢复这些数据的必要信息(比如预测信息,即运动向量、帧内预测方向)之后,我们该怎么把这些信息有序地打包起来。每一种压缩标准都有自己的bitstream format,但是都大差不差,遵循着一样的基本原则。 下面附上不同压缩标准的bitstream format:VP9 比特流,H.265(HEVC), AV1 比特流。
这一步不太涉及到技术,只是对格式标准的介绍。因为懒,我就不详细介绍了。


- 本文作者: YA
- 本文链接: https://shiyuang-scu.github.io/2023/04/28/视频压缩技术概述/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!