
上一节使用了几层简单的神经网络实现了对Fashion MNIST数据集中10种衣物的识别。我们将一张图的每一个像素都作为一个参考因素,来训练我们的模型,但是其实一张图有很多没有用的地方,这就给训练模型增加了负担。那么接下来要学习的,就是一种能够少注意图像冗余信息,多注意图像重要信息的模型。本节包括week3和week4的内容。
week3讲述了CNN,卷积神经网络,一种压缩图像、获取图像特征的模型。本节首先概述CNN的重要概念:卷积,池化,然后使用TF实现这两个概念,搭建一个卷积神经网络,在Fashion MNIST中训练。
Fashion MNIST的图片是28*28的小图,且所有的物体都居中展示。week4则将进一步学习如何使用TF的API对更大、更复杂、更不整齐的图像进行预处理,并且在预处理后的图像上施展CNN的魔法。
Enhancing Vision with Convolutional Neural Networks
主要内容
- 卷积与池化
- 使用卷积神经网络,提高上一节中仅使用两层神经网络识别Fashion MNIST 中10种衣物的准确率
Convolution
对于每一个像素,我们要求不仅关注这个像素,还要关注这个像素周围的像素。如果我们有一个filter 大小为3*3,那么我们就会关注这个像素上下左右一圈的8个像素,我们关注它们的方法就是将每个像素和filter中对应的值相乘,最后再一起相加。
上例子:
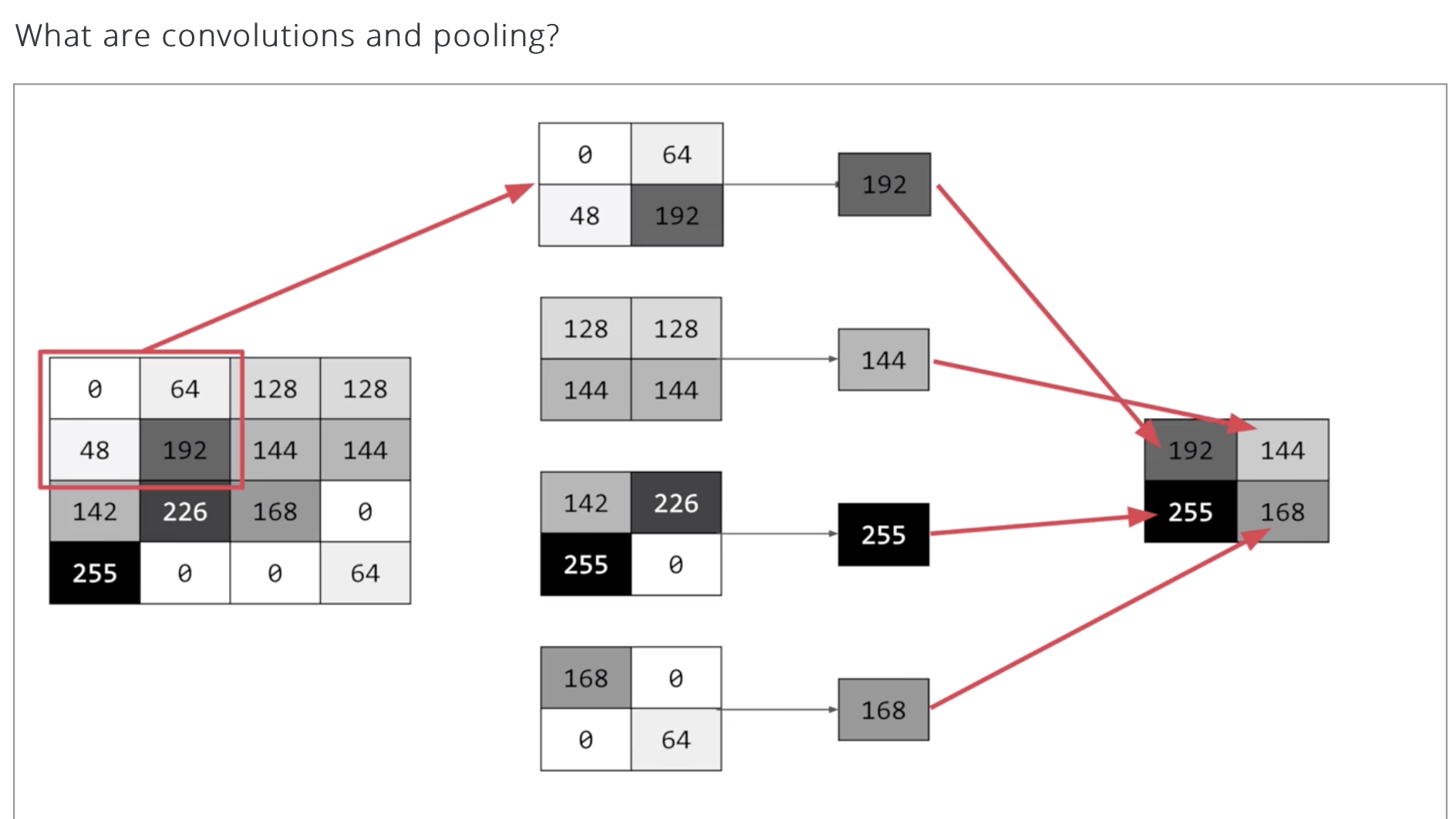
filter就这样一直滑动,每一次滑动得到一个值,每个值拼在一起,形成一张新的图像。filter还有滑动步长,stride,一次走一步,还是两步,得到的结果也会不一样。
filter滑动后的新图像大小有一个公式:
$$OutputSize=(N-F)/stride+1$$
where N 是原始图像宽度,F是filter的大小。这里默认padding=0。
卷积是一种神奇的方法,就是通过filter的过滤,能够使得图片的某些特征得到强调,filter的值不同,提取的特征就会不同。
如下图,就通过一个简单的filter得到了事物的轮廓。
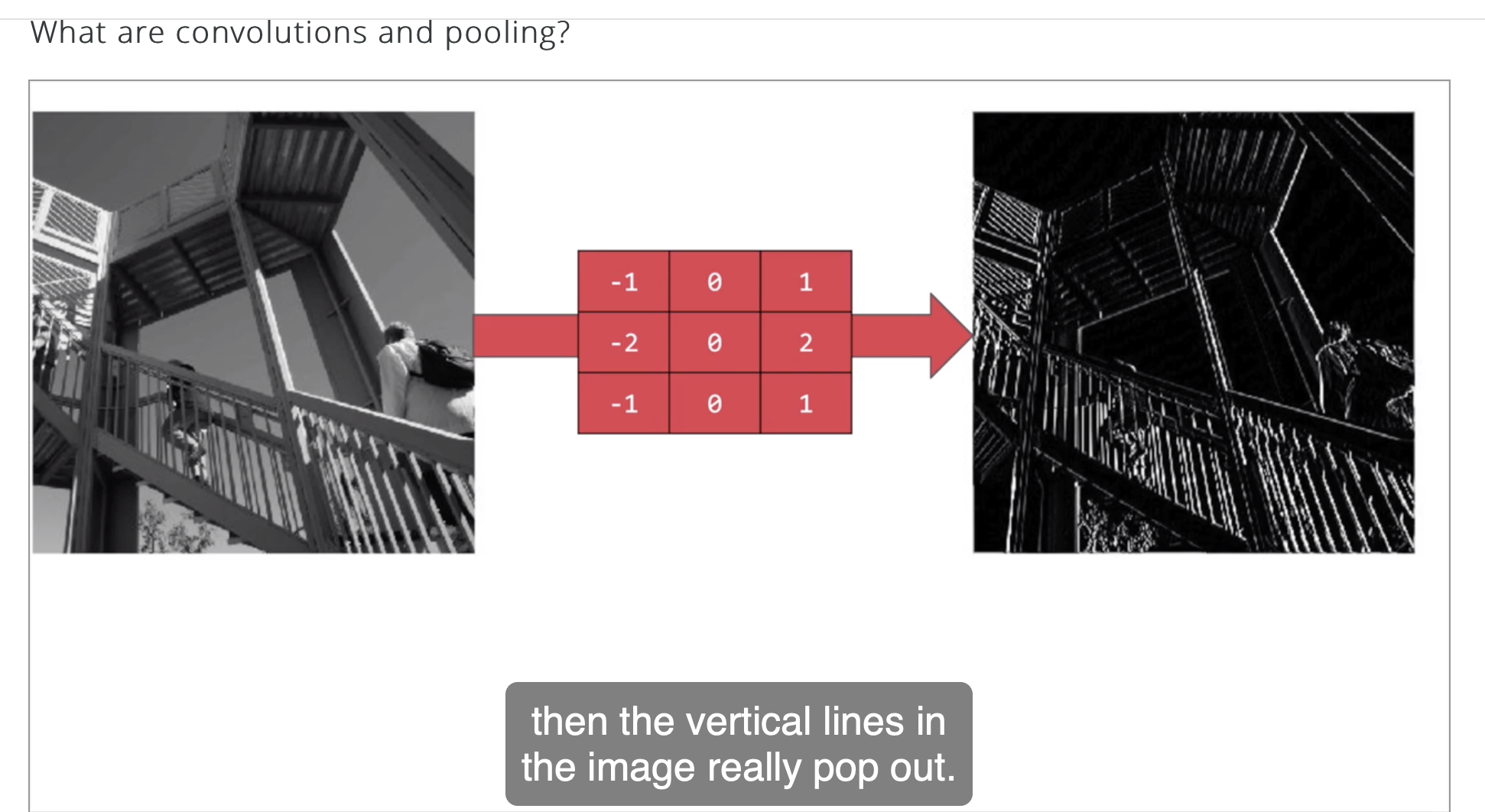
这就是卷积,一种提取图片特征的方法。
这种做法的两个关键启发:
- Features are hierarchical。从低复杂度的特征中组合出高复杂度的特征,比直接学习高复杂度的特征更加有效。比如我可以先学习识别直线、圆形之类的分类器,再训练一个组合圆形、直线这些基本图形的分类器
- Features are translationally invariant。可以保证特征的平移不变性(一定程度),可以提高模型的泛化效果。
from 【CS20-TF4DL】06 Convnet 简介
Pooling
池化的目的是为了缩小图像,将一些冗余的信息直截了当的去掉。
这里只讲Max Pooling,简单来说就是在一定区域中,比如2 * 2的像素中,选择像素值最大的像素,其他全部抛弃。
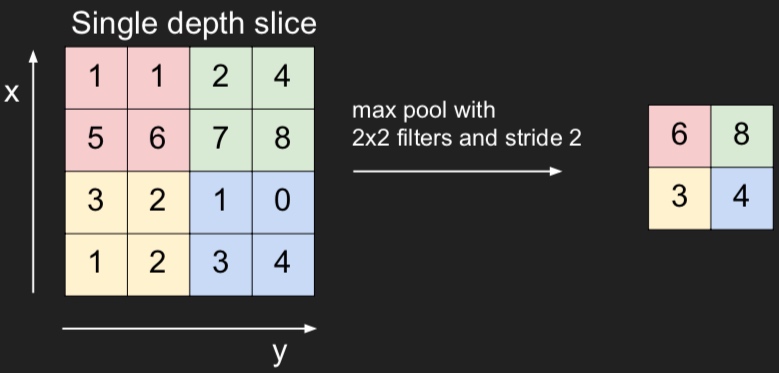
也可以把max pooling想象成有一个filter,在图像上滑动,滑动的步伐大小叫stride。
一般来说,stride会和filter一样大小,上图中,filter=2 * 2,stride=2。图像小了一半。
我们接着看例子,下图是一个经过卷积的图片:

我们使用filter大小为2*2的max pooling,使图片变成了原来的一半,非常神奇的是,缩小了一半的图片不仅没有失去原来的特征,反而更加明显了,这说明池化使得图片的冗余信息减少了。

从上面这个例子看,pooling能够有效地减少冗余信息。
Convolution & Pooling in TF
讲完了理论,接下来看代码。我们在上一节的全连接神经网络上增加了卷积和池化层:
1 | model = tf.keras.models.Sequential([ |
model.summary
model.summary能够显示模型的网络结构,下图是我们的网络结构:
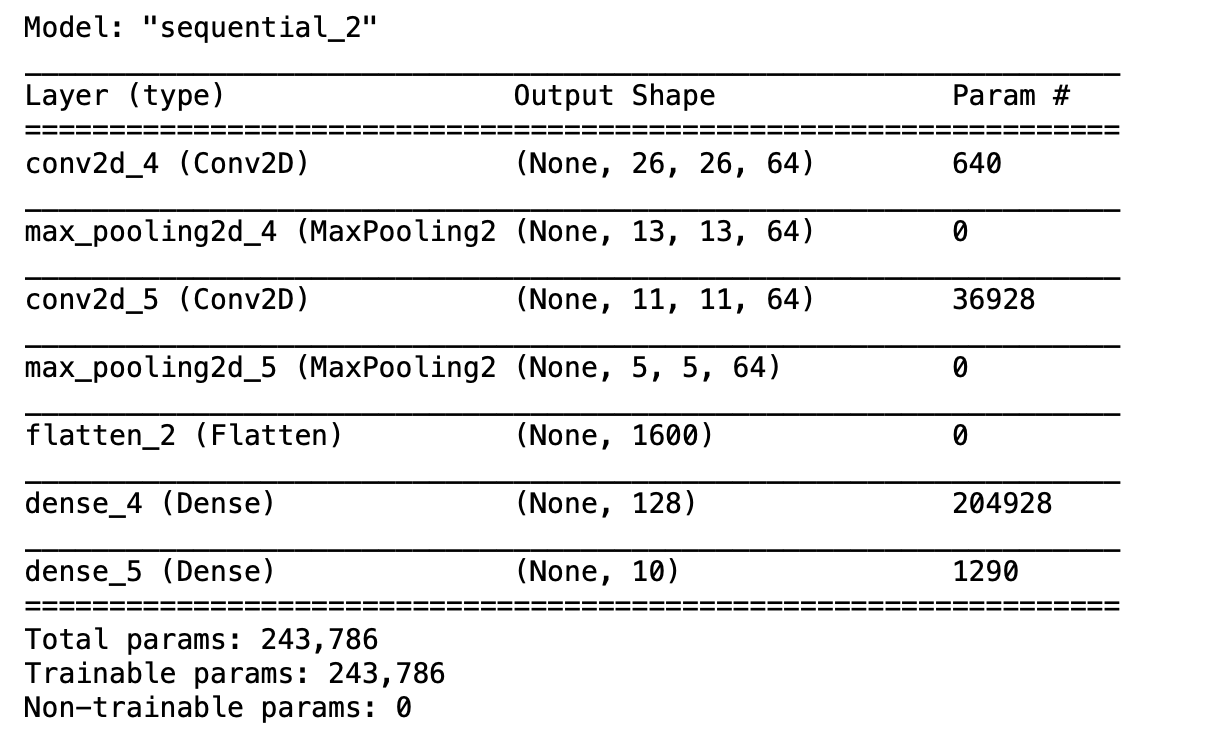
一层层看,第一层卷积层,输出的shape由原来的(28, 28, 1)变成了(26,26,64),第二层pooling后,因为filter为2*2,所以之间变为原来的一半(13, 13, 64),再经过一层卷积核池化,到最后输出为(5, 5, 64)。
一张28*28的图片,在经过卷积池化后,变成了64张5*5的图片,我们可以直观地理解为,提取了64个这张图片的特征,每个特征大小为5*5。
Using Real-world Images
主要内容
- 处理复杂、不统一的数据集:image generator
- 使用处理后的数据集训练:fit generator
Image Generator
我们之前使用的都是非常完美的数据集,图片大小相同、物体居中且清晰,但是当我们有一个数据集,里面的图片大小不同,且物体的位置并不居中,图中有不止一个物体,而且更糟糕的是,我们还没做label,该怎么办?别怕,用TF的API:image generator。
只要我们把同一类的图片放在同一个文件夹下,我们就能用这个API来自动打标签,标签就是这个文件夹的名字。
如图,我的图片都没打标签,但是都放在了文件夹里,那么就可以放心地用image generator了。
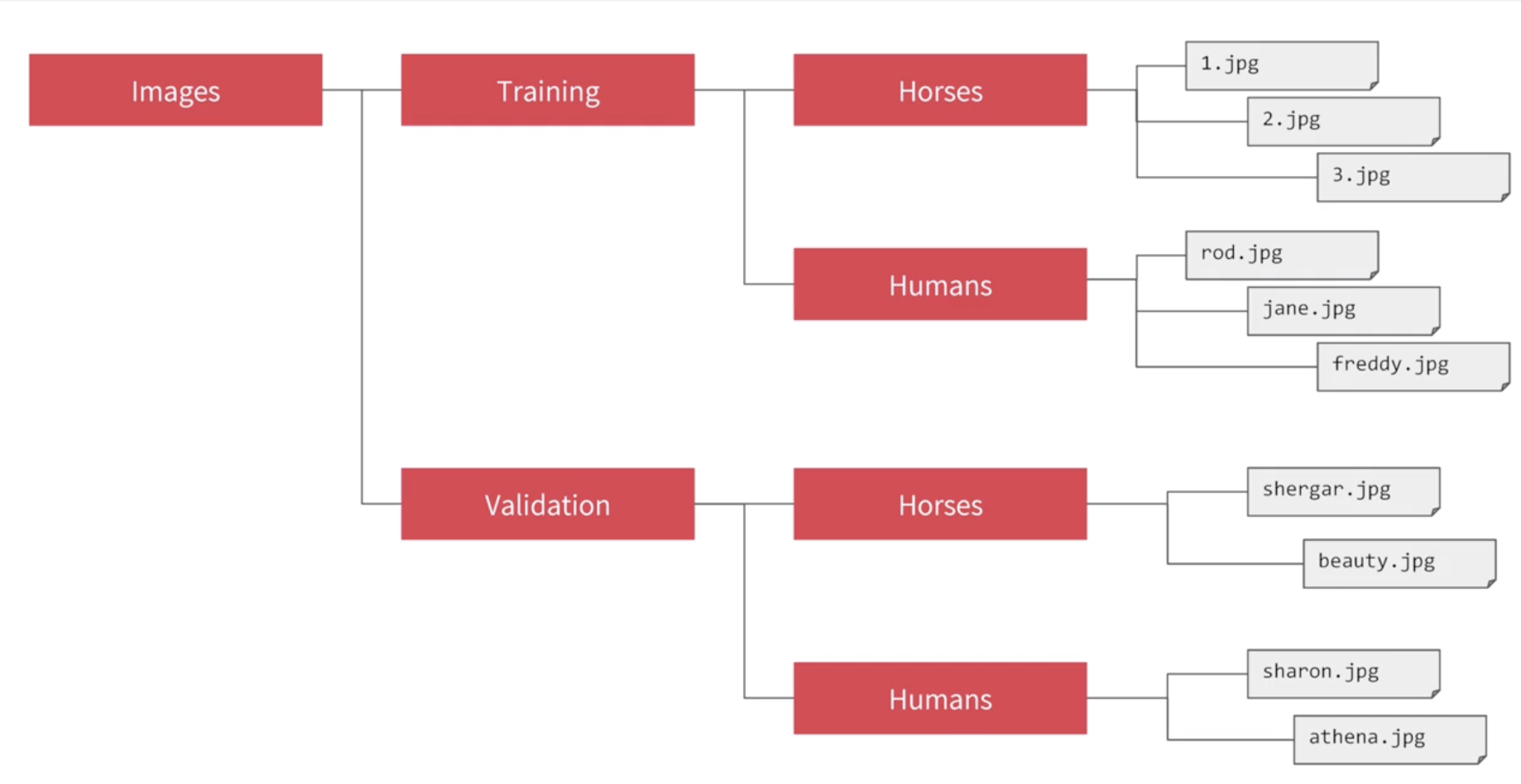
实现的代码如下:
1 | from tensorflow.keras.preprocessing.image import ImageDataGenerator |
CNN on Complex Images
Model
对于更复杂的数据集,我们定义了一个更大的卷积神经网络,代码如下:
1 | model = tf.keras.models.Sequential([ |
和上一节差不多,多了两组卷积池化层,就不解释了。
Compile
上一节compile的optimizer是adam,loss是“sparse_categorical_crossentropy”,这次optimizer换成“RMSprop”,loss换成“binary_crossentropy”。RMSprop使得梯度下降变得更加稳定,且能容忍更大的学习率。
代码如下:
1 | from tensorflow.keras.optimizers import RMSprop |
Training
还记得之前的fit吗?
1 | model.fit(x_train, y_train, epochs=10) |
因为这次我们的x_train不是直接从数据集里拿的,而是使用ImageDataGenerator这个API对数据进行预处理,所以相应的fit也要改。
名字和ImageDataGenerator 很般配:fit_generator。是这样用的:
1 | history = model.fit_generator( |
Validation
我们可以在训练的时候,增加一组验证集。
验证集的预处理和训练集的预处理一样:
1 | from tensorflow.keras.preprocessing.image import ImageDataGenerator |
在原来的fit_generator中加入validate_generator即可:
1 | history = model.fit_generator( |


- 本文作者: YA
- 本文链接: https://shiyuang-scu.github.io/2019/10/31/【Introduction-to-TensorFlow】03-卷积神经网络与复杂数据集/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!